Exchange Server 2013 is a major new
release and, as such, the Exchange product group invested in the key
development areas that were projected to yield the largest benefits to
both customers and the teams that run Exchange Online. A number of the
product revisions centered on database and storage issues, many of
which were needed to address problems in Exchange Server 2010, while
others were added to deal with trends within the industry that Exchange
2013 would need during its 10-year life cycle. For example, the
following issues existed in Exchange Server 2010 and needed to be
resolved.
Issue 1: Storage Capacity Increasing
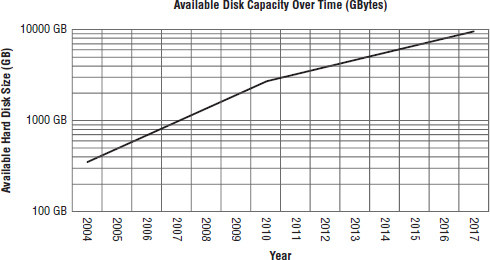
As shown in Figure 1,
magnetic disk areal density has been increasing dramatically. This
directly affects how much capacity each drive platter can store and
thus how much capacity a drive of each form factor can provide.
Historically, areal density increased by 40 percent a year. In 2010,
however, the IEEE suggested that this increase had slowed to 20 percent
a year.
Exchange Server 2010 had started to make
better use of larger capacity disks. However, trying to use a spindle
much larger than 2 TB JBOD was problematic because of Microsoft's
recommendation not to exceed a 2 TB mailbox database and not to store
multiple mailbox databases on a single spindle.
During the life cycle of Exchange Server
2013, most storage vendors are predicting that they will be making 6
TB–8 TB 3.5″ 7.2K rpm disk drives. Ideally, this means that Exchange
Server 2013 should be able to use an 8 TB 7.2K rpm spindle.
FIGURE 1 Areal density increase over time
Issue 2: Mechanical Disk IOPS Performance Not Increasing
Despite constant increases in areal density and
storage capacity, the random IOPS performance for mechanical disk
drives has remained fairly static. This is largely due to the physics
involved in mechanical hard drive I/O performance. The obvious question
is, why don't we use solid-state (SSD) technology, which can provide extremely high IOPS for each device? Not surprisingly, the answer is cost, as shown in Table 1.
TABLE 1: SSD vs. mechanical hard drive cost (at time of writing)

The prices in Table 1
show that solid-state drives are almost 15 times more expensive than
mechanical hard disk drives when compared on a price-per-GB rating.
Additionally, there are concerns about the longevity of solid-state
memory for use with enterprise database workloads such as Exchange
Server. There are storage solutions where a small number of high-speed
SSD devices can be used as a form of secondary disk cache that provides
higher performance without the high cost. In most cases, however, these
solutions are extremely expensive when compared with an equal-size,
directly attached storage solution. They may also result in
unpredictable performance for random workloads.
Given this difference in cost between SSD
and mechanical hard disk drives, SSDs are not recommended for Exchange
Server storage. This leaves design teams with a common problem, that
is, how to calculate the random IOPS capability for a mechanical hard
disk drive. As a matter of fact, there is a relatively simple method for deriving random IOPS per spindle given two commonly available metrics.
Average Seek Time This is the average time for the disk head to reach its required position on the disk platter.
Rotational Speed in rpm This is the speed at which the disk platters spin.
Once these values are known, it is
possible to determine how many random IOPS the disk spindle can
accommodate. Review the following example:
Manufacturer Supplied Information
- Spindle speed: 7,200 rpm
- Average random seek time: 8ms
CALCULATING IOPS PER SPINDLE
The number of random read and write operations
that a hard disk drive can complete is a function of how fast the disk
spins and how quickly the head can move around. Given a few metrics
about the disk drive, we can calculate the theoretical maximum random
IOPS as follows:
Time for One Rotation This involves converting rpm into seconds per rotation in order to determine how long the platter takes to spin through 360°.
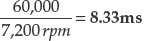
Rotational Latency This value is the time
that the platter takes to rotate through 180°. This is caused by the
head moving to the track and then waiting for the right part of the
platter to pass under it before it can read the data. On average, the
platter will have to complete 180° of rotation before it can perform
each I/O.
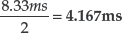
Rotational Latency + Average Seek Time
This value is the sum of rotational latency, which is the amount of
time we must wait after the head has reached the right track before it
can read the bit of data that we want, plus average seek time, which is
the time we have to wait to position the head in the first place. The
combination of the two values is the average delay before we can get
the head to the right bit of the disk platter.
4.15 + 8 ms = 12.15ms
Predicted Random IOPS This value is a
theoretical prediction of the maximum random IOPS of which the spindle
is capable. This formula calculates how many operations we can do per
ms (1/Rotational Latency + Seek Time) and then converting that into
operations per second (×1,000).
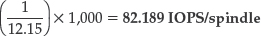
Why is this important? We are mainly
interested in this because the two factors that govern random disk IOPS
for mechanical disk drives are rotation speed and seek time. Neither of
these factors is likely to improve dramatically in the near future.
Disks have been available at up to 15K rpm spindle speeds for the last
five years or more. Nonetheless, these high-speed spindles are very
costly, and they require more power and generate more heat (thus
requiring additional cooling) than slower spindle speeds. It is also
difficult to spin a large disk platter at such high speeds, and so most
manufacturers only offer high spindle speed drives in smaller
capacities, because they require a smaller platter diameter to maintain
the high spindle speed. Minor improvements in average seek time have
been achieved as manufacturing and engineering processes have matured.
However, most storage vendors report that they do not expect to see any
significant improvements in this area.
This leaves Exchange design teams with a
problem. Disk capacities are increasing and costs per megabyte are
declining, but random IOPS performance is relatively static. This means
that we are unable to take advantage of these newer, high-capacity hard
disk drives effectively. Thus, Exchange 2013 must be able to make
better use of 7.2K rpm mechanical disk drives with greater than 2 TB
capacities.
Issue 3: JBOD Solutions Require Operational Maturity
Exchange 2010 allowed the use of JBOD. Though
initially this term was confusing within the Exchange community, for
our discussion the term JBOD will refer to the presentation of a single
disk spindle to the operating system as an available volume.
JBOD represents a very cheap and simple
way to provide Exchange storage. Ideally the JBOD spindles will be
slow, cheap disks and directly attached to each DAG node to provide the
bestcost model. The JBOD model requires three or more copies of each
database to ensure sufficient data availability in the event that a
disk spindle fails.
The most common problem area for JBOD is
not in the technology. Rather, it is what has to occur operationally
when a disk spindle inevitably fails. Since there is no RAID array,
every single disk spindle failure will result in a predictable series
of events:
- 1. Disk failure
- 2. Active workload moved to another spindle if the failed spindle was hosting an active copy
- 3. Physical disk spindle replacement
- 4. New disk brought online
- 5. New disk partitioned
- 6. New volume formatted
- 7. Database reseeded
- 8. Active workload moved back to the replaced disk if it was active in the first place
If the failed spindle
was hosting the active copy of the database at the time of failure,
there may be a minor interruption in service to the end user. However,
typically the failover times are brief enough so that Outlook clients
in cached mode will not notice this kind of failure.
Dealing with disk spindle failures in a
JBOD deployment can be largely automated via a combination of
PowerShell scripts and monitoring software. However, it does require a
level of operational maturity both to capture the alerts and to execute
the correct remediation processes once the alert is received. Compared
to a RAID based solution where a disk must be replaced, the level of
involvement, resource skills, and access requirements necessary to
repair a JBOD spindle failure is high.
Exchange Server 2013 must provide an
easier way to deal with JBOD disk spindle failures and to reduce the
operational maturity and process required to recover from such
failures.
Issue 4: Mailbox Capacity Requirements Increasing
If there is one thing that is common to every
release of Exchange Server, it is the expectation that the latest
version will be able to support ever-larger mailbox sizes. In recent
times, this expectation has also grown to include mailbox item counts.
With Exchange Server 2010, the ability to
store ever more data in the Exchange database via features such as
In-Place Hold and single-item recovery meant that mailbox sizes
increased dramatically.
IN-PLACE HOLD
In-Place Hold is a mechanism whereby an
administrator can retain all contents in a mailbox, even if the end
user deletes them. This is extremely useful in scenarios such as
litigation or where organizations need to persist end-user data for
internal review.
Many customers want to store all mailbox
data within Exchange for both the real-time message service and
compliance. Exchange Server 2013 must be able to maintain performance
when clients are connected to these extremely large mailboxes.
Issue 5: Everything Needs to Be Cheaper
A common thread in Exchange projects is cost
reduction. This encompasses not only the cost of the hardware but also
running costs, datacenter costs, and network, power, cooling, and
migration costs as well. As customer requirements have increased,
Exchange has had to meet these needs and do so without spiraling costs
upward. This is particularly evident with storage, where the
requirements for capacity and performance have expanded dramatically
while the demands for cost reduction have been equally dramatic.
Recent trends have placed an increasing
focus on power, heating, cooling, and datacenter space. Organizations
are looking for new ways to reduce their operating costs. Exchange
infrastructure can often contribute significantly in large deployments,
especially when the storage and supporting functions are considered,
such as backup, monitoring, publishing, and so on.
Consolidation of roles was a
common theme for Exchange 2010 projects, with many customers taking
advantage of high-density locally attached storage, such as the HP MDS
600, which could provide 70 × 3.5″ SAS disks in 5U of rack space.
Additionally, customers could take advantage of
multi-role Exchange deployments to reduce the server footprint. This
was a substantial improvement over previous versions of Exchange, and
it allowed large-scale consolidation of servers and storage into fewer,
more easily managed datacenters. However, power, cooling, and
datacenter space costs are increasing. Exchange Server 2013 must
continue this trend of consolidation while meeting the increasing
business and operational demands for a robust enterprise-messaging
product.