A deployment is scaled by creating new slaves and adding them to the
collection of computers you have. The term replication
topology refers to the ways you connect servers using replication.
Figure 1 shows some
examples of replication topologies: a simple topology, a tree topology, a dual-master topology, and a circular topology.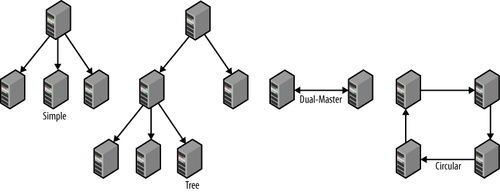
These topologies are used for different purposes: the dual-master
topology handles failovers elegantly, for example, and circular
replication and dual masters allow different sites to work locally while
still replicating changes over to the other sites.
The simple and tree topologies are used for scale-out. The use of
replication causes the number of reads to greatly exceed the number of
writes. This places special demands on the deployment in two ways:
It requires load balancing
We’re using the term load balancing here to
describe any way of dividing queries among servers. Replication
creates both reasons for load balancing and methods for doing so.
First, replication imposes a basic division of the load by
specifying writes to be directed to the masters while reads go to
the slaves. Furthermore, you sometimes have to send a particular
query to a particular slave.
It requires you to manage the topology
Servers crash sooner or later, which makes it necessary to
replace them. Replacing a crashed slave might not be urgent, but
you’ll have to replace a crashed master quickly.
In addition to this, if a master crashes, clients have to be
redirected to the new master. If a slave crashes, it has to be taken
out of the pool of load balancers so no queries are directed to
it.
To handle load balancing and management, you should put tools in
place to manage the replication topology, specifically tools that monitor
the status and performance of servers and tools to handle the distribution
of queries.
For load balancing to be effective, it is necessary to have spare
capacity on the servers. There are a few reasons for ensuring you have
spare capacity:
Peak load handling
You need to have margins to be able to handle peak loads. The load
on a system is never even but fluctuates up and down. The spare
capacity necessary to handle a large deployment depends a lot on the
application, so you need to monitor it closely to know when the
response times start to suffer.
Distribution cost
You need to have spare capacity for running the replication
setup. Replication always causes a “waste” of some capacity on the
overhead of running a distributed system. It involves extra queries
to manage the distributed system, such as the extra queries
necessary to figure out where to execute a read query.
One item that is easily forgotten is that each slave has to perform the
same writes as the master. The queries from the master are executed
in an orderly manner (that is, serially), with no risk of
conflicting updates, but the slave needs extra capacity for running
replication.
Administrative tasks
Restructuring the replication setup requires spare capacity so you can
support temporary dual use, for example, when moving data between
servers.
Load balancing works in two basic ways: either the application asks
for a server based on the type of query, or an intermediate layer—usually
referred to as aproxy—analyzes the query and sends it
to the correct server.
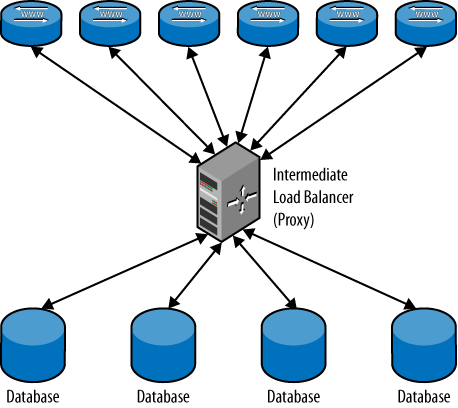
Using an intermediate layer to analyze and distribute the queries (as shown in Figure 2) is by far the most
flexible approach, but it has two disadvantages:
Processing resources have to be spent on analyzing queries. This
delays the query, which now has to be parsed and analyzed twice: once
by the proxy and again by the MySQL server. The more advanced the
analysis, the more the query is delayed. Depending on the application,
this may or may not be a problem.
Correct query analysis can be hard to implement, sometimes even
impossible. A proxy will often hide the internal structure of the
deployment from the application programmer so that she does not have
to make the hard choices. For this reason, the client may send a query
that can be very hard to analyze properly and might require a
significant rewrite before being sent to the servers.
One of the tools that you can use for proxy load balancing
is MySQL Proxy. It contains a full implementation of the MySQL
client protocol, and therefore can act as a server for the real client
connecting to it and as a client when connecting to the MySQL server. This
means that it can be fully transparent: a client can’t distinguish between
the proxy and a real server.
The MySQL Proxy is controlled using the Lua programming
language. It has a built-in Lua engine that executes small—and
sometimes not so small—programs to intercept and manipulate both the
queries and the result sets. Since the proxy is controlled using a real
programming language, it can carry out a variety of sophisticated tasks,
including query analysis, query filtering, query manipulation, and query
distribution.
The precise methods for using a proxy depend entirely on the type of
proxy you use, so we will not cover that information here. Instead, we’ll
focus on using a load balancer in the application layer. There are a
number of load balancers available, including:
It is also possible to distribute the load on the DNS level and to
handle the distribution directly in the application.
1. Example of an Application-Level Load Balancer
Let’s tackle the task of designing and implementing a simple
application-level load balancer to see how it works. In this section,
we’ll implement read/write splitting.
The most straightforward approach to load balancing at the
application level is to have the application ask the load balancer for a
connection based on the type of query it is going to send. In most
cases, the application already knows if the query is going to be a read
or write query and also which tables will be affected. In fact, forcing
the application developer to consider these issues when designing the
queries may produce other benefits for the application, usually in the
form of improved overall performance of the system. Based on this
information, a load balancer can provide a connection to the right
server, which the application then can use to execute the query.
A load balancer on the application layer needs to have a central
store with information about the servers and what queries they should
handle. Functions in the application layer send queries to this central
store, which returns the name or IP address of the MySQL server to
query.
Let’s develop a simple load balancer like the one shown in Figure 3 for use by the
application layer. We’ll use PHP for the presentation logic because it’s so popular on
web servers. It is necessary to write functions for updating the server
pool information and functions to fetch servers from the pool.
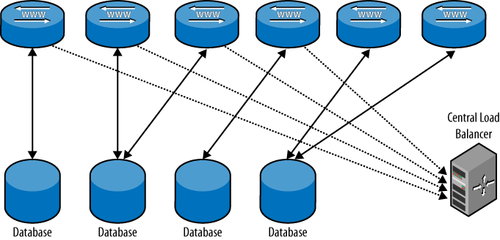
The pool is implemented by creating a table with all the servers
in the deployment in a common database that is shared by all nodes. In
this case, we just use the host and port as primary key for the table
(instead of creating a host ID) and create a common
database to contain the tables of the shared data.
Note:
You should duplicate the central store so that it doesn’t create
a single point of failure. In addition, because the list of available
servers does not often change, load balancing information is a perfect
candidate for caching.
For the sake of simplicity—and to avoid introducing dependencies
on other systems—we demonstrate the application-level load balancer
using a pure MySQL implementation.
There are many other techniques that you can use that do not
involve MySQL. The most common technique is to use round-robin DNS;
another alternative is using Memcached, which is a distributed
in-memory key/value store.
Also note that the addition of an extra query might be a
significant overhead for high-performing systems and should be
avoided.
The load balancer lists servers in the load balancer pool,
separated into categories based on what kind of queries they can handle.
Information about the servers in the pool is stored in a central
repository. The implementation consists of a table in the common
database given in Example 1, the PHP functions in
Example 2 for querying
the load balancer from the application, and the Python functions in
Example 3 for updating
information about the servers.
Example 1. Database tables for the load balancer
CREATE TABLE nodes (
host CHAR(28) NOT NULL,
port INT UNSIGNED NOT NULL,
sock CHAR(64) NOT NULL,
type SET('READ','WRITE') NOT NULL DEFAULT '',
PRIMARY KEY (host, port)
);
|
We store for each host regarding whether it accepts reads, writes,
both, or neither. This information is stored in the type field. By setting it to the empty set, we
can bring the server offline, which is important for maintenance.
A simple SELECT will suffice to
find all the servers that can accept the query. Since we want just a
single server, we limit the output to a single line using the LIMIT modifier to the
SELECT query, and to distribute
queries evenly among available servers, we use the ORDER BY RAND() modifier.
Note:
Using the ORDER BY RAND()
modifier requires the server to sort the rows in the table, which may
not be the most efficient way to pick a number randomly (it’s actually
a very bad way to pick a number randomly), but we picked this approach
for demonstration purposes only.
Example 2 shows
the PHP function getServerConnection,
which queries for a server and connects to it. It returns a connection
to the server suitable for issuing a query, or NULL if no suitable server can be found. The
helper function connect_to constructs
a suitable connection string given its host, port, and a Unix socket. If
the host is localhost, it will use
the socket to connect to the server for efficiency.
Example 2. PHP function for querying the load balancer
function connect_to($host, $port, $socket) {
$db_server = $host == "localhost" ? ":{$socket}" : "{$host}:{$port}";
return mysql_connect($db_server, 'query_user');
}
$COMMON = connect_to(host, port, socket);
mysql_select_db('common', $COMMON);
define('DB_WRITE', 'WRITE');
define('DB_READ', 'READ');
function getServerConnection($queryType)
{
global $COMMON;
$query = <<<END_OF_SQL
SELECT host, port, sock FROM nodes
WHERE FIND_IN_SET('$queryType', type)
ORDER BY RAND() LIMIT 1
END_OF_SQL;
$result = mysql_query($query, $COMMON);
if ($row = mysql_fetch_row($result))
return connect_to($row[0], $row[1], $row[2]);
return NULL;
}
|
The final task is to provide utility functions for adding and
removing servers and for updating the capabilities of a server. Since
these are mainly to be used from the administration logic, we’ve
implemented this function in Python using the Replicant
library. The utility consists of three functions:
pool_add(common, server,
type)
Adds a server to the
pool. The pool is stored at the server denoted by common, and the type to use is a list—or other
iterable—of values to set.
pool_del(common,
server)
Deletes a server from the pool.
pool_set(common, server,
type)
Changes the type of the server.
Example 3. Administrative functions for the load balancer
class AlreadyInPoolError(replicant.Error):
pass
_INSERT_SERVER = """
INSERT INTO nodes(host, port, sock, type)
VALUES (%s, %s, %s, %s)"""
_DELETE_SERVER = "DELETE FROM nodes WHERE host = %s AND port = %s"
_UPDATE_SERVER = "UPDATE nodes SET type = %s WHERE host = %s AND port = %s"
def pool_add(common, server, type=[]):
common.use("common")
try:
common.sql(_INSERT_SERVER,
(server.host, server.port, server.socket, ','.join(type)));
except MySQLdb.IntegrityError:
raise AlreadyInPoolError
def pool_del(common, server):
common.use("common")
common.sql(_DELETE_SERVER, (server.host, server.port))
def pool_set(common, server, type):
common.use("common")
common.sql(_UPDATE_SERVER, (','.join(type), server.host, server.port))
|
These functions can be used as shown in the following examples:
pool_add(common, master, ['READ', 'WRITE'])
for slave in slaves:
pool_add(common, slave, ['READ'])