Logical and Physical Operator Icons
If
you want to better understand the graphical execution plans displayed
in SSMS, it helps to be able to recognize what each of the displayed
icons represents. Recognizing them is especially valuable when you need
to quickly locate operations that appear out of place for the type of
query being executed. The following sections cover the more common
logical and physical operators displayed in the Query Analyzer execution
plans.
Assert
Assert is used to verify
a condition, such as referential integrity (RI) or check constraint, or
to ensure that a scalar subquery returns only a single row. It acts as
sort of a roadblock, allowing a result stream to continue only if the
check being performed is satisfied. The argument displayed in the Assert
ToolTip spells out each check being performed.
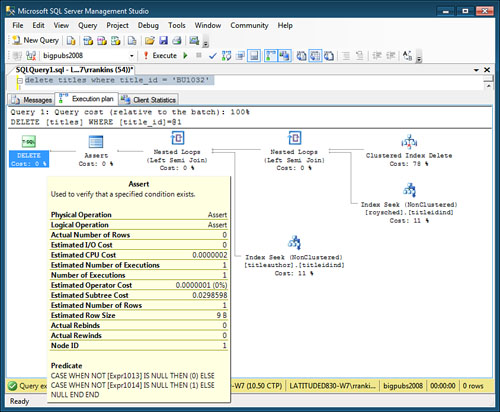
For example, a deletion from the titles table in the bigpubs2008 database has to be verified to ensure that it doesn’t violate referential integrity with the sales and titleauthors table. The reference constraints need to check that the title_id being deleted does not exist in either the sales or titleauthors tables. If the result of the Assert returns a NULL, the stream continues through the query. Figure 5
shows the estimated execution plan and ToolTip of the Assert that
appears for a delete on titles. The Predicate indicates that the
reference constraint rejects any case in which the matching foreign key
expression that returns from both child tables is NOT NULL. Notice that it returns a different value (0 or 1), depending on the table on which the foreign key violation occurs so that the appropriate error message can be displayed.
Clustered Index Delete
, Insert
, and Update
The Clustered Index
physical operators Delete, Insert, and Update indicate that one or more
rows in the specified clustered index are being deleted, inserted, or
updated. The index or indexes affected by the operation are specified in
the Object item of the ToolTip. The Predicate indicates which rows are
being deleted or which columns are being updated.
Nonclustered Index Delete
, Insert
, and Update
Similar to the Clustered
Index physical operators Delete, Insert, and Update, the Nonclustered
Index physical operators Delete, Insert, and Update indicate that one or
more rows in the specified nonclustered index are being deleted,
inserted, or updated.
Clustered Index Scan
and Seek
A Clustered Index Seek is a
logical and physical operator that indicates the Query Optimizer is
using the clustered index to find the data rows via the index pointers. A
Clustered Index Scan (also a logical and physical operator) indicates
whether the Query Optimizer
is scanning all or a subset of the table or index rows. Note that a
table scan against a table with a clustered index displays as a
Clustered Index Scan; the Query Optimizer is performing a full scan
against all data rows in the table, which are in clustered key order.
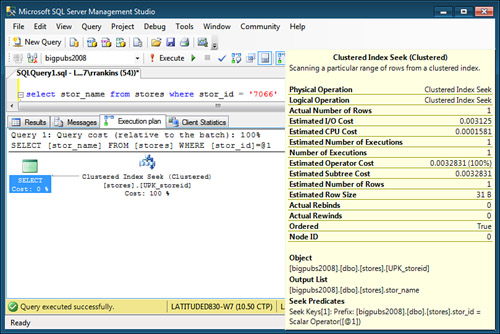
Figure 6 shows a Clustered Index Seek ToolTip. The ToolTip indicates that the seek is being performed against the UPK_Storeid index on the stores
table. The Seek Predicates item indicates the search predicate being
used for the lookup against the clustered index, and the Query Optimizer
determines that the results will be output in clustered index order, as
indicated by the Ordered item indicating true.
Nonclustered Index Scan
and Seek
A Nonclustered Index
Seek is a logical and physical operator that indicates the Query
Optimizer is using the nonclustered index to find the data rows via the
index pointers. A Nonclustered Index Scan (also a logical and physical
operator) indicates whether the Query Optimizer is scanning all or a
subset of the nonclustered index rows. The Seek Predicates item in a
Nonclustered Index Seek operator identifies the search predicate being
used for the lookup against the nonclustered index. The Ordered item in
the ToolTip indicates true if the rows will be returned in nonclustered index key order.
Collapse
and Split
A Split physical and
logical operator indicates that the Query Optimizer has decided to break
the rows’ input from the previous update optimization step into a
separate delete and insert operation. The Estimated Number of Rows in
the Split icon ToolTips is normally double the input row count,
reflecting this two-step operation. If possible, the Query
Optimizer might choose later in the plan to collapse those rows,
grouping by a key value. The collapse typically occurs if the query
processor encounters adjacent rows that delete and insert the same key
values.
Compute Scalar
The Query Optimizer uses
the Compute Scalar operator to output a computed scalar value. This
value might be returned in the result set or used as input to another
operation in the query, such as a Filter operator. You might see this
operator when data values that are feeding an input need to be converted
to a different data type first.
Concatenation
[
The Concatenation
operator indicates that the result sets from two or more input sources
are being concatenated into a single output. You often see this when a UNION ALL is being used. You can force a concatenation union strategy by using the OPTION clause in the query and specifying a CONCAT UNION.
Constant Scan
The Constant Scan
operator introduces one or more constant rows into a query. A Compute
Scalar operation sometimes is used to provide input to the Constant Scan
operator. A Compute Scalar operator often follows a Constant Scan
operator to add columns to any rows produced by the Constant Scan
operator.
Deleted Scan
and Inserted Scan
The Deleted Scan and
Inserted Scan icons in the execution plan indicate that a trigger is
being fired and that within that trigger, the Query Optimizer needs to
scan either the deleted or inserted tables.
Filter
The Filter icon indicates
that the input rows are being filtered according to the predicate
indicated in the ToolTip. This operator is used primarily for
intermediate operations that the Query Optimizer needs to perform.
Hash Match
In a hash join, the keys common
between the two tables are hashed into a hash bucket, using the same
hash function. This bucket usually starts out in memory and then moves
to disk as needed. The type of hashing that occurs depends on the amount
of memory required. Hashing is commonly used for inner and outer joins,
intersections, unions, and differences. The Query Optimizer often uses
hashing for intermediate processing.
A hash join requires at least
one equality clause in the predicate, which includes the clauses used to
relate a primary key to a foreign key. Usually, the Query Optimizer
selects a hash join when the input tables are unsorted or are different
in size, when no appropriate indexes
exist, or when specific ordering of the result is not required. Hash
joins help provide better query performance for large databases, complex
queries, and distributed tables.
A hash match operator
uses the hash join strategy and might also include other criteria to be
considered a match. The other criteria are indicated in the Probe Residual clause shown in the Hash Match ToolTip.
Nonclustered Index Spool
, Row Count Spool
, and Table Spool
An Index Spool, Row Count Spool, or Table Spool icon indicates that the rows are being stored in a hidden spool table in the tempdb
database, which exists only for the duration of the query. Generally,
this spool is created to support a nested iteration operation because
the Query Optimizer might need to use the rows again. If the operator is
rewound (for example, by a Nested Loops operator) but no rebinding is
needed, the spooled data is used instead of rescanning the input data.
Often, you see a Spool icon
under a Nested Loops icon in the execution plan. A Table Spool ToolTip
does not show a predicate because no index is used. An Index Spool
ToolTip shows a SEEK predicate. A
temporary work table is created for an index spool, and then a temporary
index is created on that table. These temporary work tables are local
to the connection and live only as long as the query.
The Row Count Spool
operator counts how many rows are present in the input and returns just
the number of rows. This operator is used when checking for the
existence of rows, rather than the actual data contained in the rows
(for example, an existence subquery or an outer join when the actual
data from the inner side is not needed).
Eager Spool
or Lazy Spool
The Query Optimizer selects to
use either an Eager or Lazy method of filling the spool, depending on
the query. The Eager method means that the spool table is built all at
once upon the first request for a row from the parent operator. The Lazy
method builds the spool table as a row is requested by its parent
operator.
Log Row Scan
The Log Row Scan icon indicates that the transaction log is being scanned.
Merge Join
The merge join is a strategy
requiring that both the inputs be sorted on the common columns, defined
by the predicate. The Merge Join operator may be preceded by an explicit
sort operation in the query plan. A merge join performs one pass
through each input table, matching the columns defined in the WHERE or JOIN
clause as it steps through each input. A merge join looks similar to a
simple nested loop but uses only a single pass of each table.
Occasionally, you might see an additional sort operation prior to the
merge join operation when the initial inputs are not sorted properly.
Merge joins are often used to perform inner joins, left outer joins,
left semi-joins, left anti-semi-joins, right outer joins, right
semi-joins, right anti-semi-joins, and union logical operations.
Nested Loops
Nested
loop joins are also known as nested iteration. Basically, in a nested
iteration, every qualifying row in the outer table is compared to every
qualifying row in the inner table. This is why you may at times see a
Spool icon of some sort providing input to a Nested Loop icon. This
allows the inner table rows to be reused (that is, rewound). When every
row in each table is being compared, it is called a naïve nested loops
join. If an index is used to find the qualifying rows, it is referred to
as an index nested loops join. Nested loops can be used to perform
inner joins, left outer joins, left semi-joins, and left
anti-semi-joins.
The number of comparisons
performed for a nested loop join is the calculation of the number of
outer rows times the estimated number of matching inner rows for each
lookup. This can become expensive. Generally, a nested loop join is
considered to be most effective when both input tables are relatively
small.
Parameter Table Scan
The Parameter Table Scan icon
indicates that a table is acting as a parameter in the current query.
Typically, this icon is displayed when INSERT queries exist in a stored procedure.
Remote Delete
, Remote Insert
, Remote Query
, Remote Scan
, and Remote Update
The Remote Delete, Remote
Insert, Remote Query, Remote Scan, and Remote Update operators indicate
that the operation is being performed against a remote object such as a
linked table.
RID Lookup
The RID Lookup
operator indicates that a bookmark lookup is being performed on a heap
table using a row identifier (RID). The ToolTip indicates the bookmark
label used to look up the row and the name of the table in which the row
is being looked up. The RID Lookup operator is always accompanied by a
Nested Loop Join operator.
Sequence
The Sequence operator
executes each operation in its child node, moving from top to bottom in
sequence, and returns only the end result from the bottom operator. You
see this most often in the updates of multiple objects.
Sort
The Sort operator indicates that the input is being sorted. The sort order is displayed in the ToolTip’s Order By item.
Stream Aggregate
You most often see the Stream Aggregate operation when you are aggregating a single input, such as a DISTINCT clause or a SUM, COUNT, MAX, MIN, or AVG operator. The output of this operator may be referenced by later operators in the query, returned to the client, or both.
Because the Stream
Aggregate operator requires input ordered by the columns within its
groups, a Sort operator often precedes the Stream Aggregate operator
unless the data is already sorted due to a prior Sort operator or due to
an ordered index seek or scan.
Table Delete
, Table Insert
, Table Scan
, and Table Update
You see the Table Delete,
Table Insert, Table Scan, and Table Update operators when the indicated
operation is being performed against that table as a whole. The presence
of these operators does not always mean a problem exists, although a
table scan can be an indicator that you might need some indexes to
support the query. A table scan may be performed on small tables even if
appropriate indexes exist, especially when the table is only a single
page or two in size.
Table-valued Function
The Table-valued Function
operator is displayed for queries with calls to table-valued functions.
The Table-valued Function operator evaluates the table-valued function,
and the resulting rows are stored in the tempdb database. When the parent operators request the rows, the Table-valued Function operator returns the rows from tempdb.
Top
The Top operator indicates a
limit that is set, either by number of rows or a percentage, on the
number of results to be returned from the input. The ToolTip may also
contain a list of the columns being checked for ties if the WITH TIES option has been specified.
Parallelism Operators
The Parallelism operators
indicate that parallel query processing is being performed. The
associated logical operator displayed is one of the Distribute Streams,
Gather Streams, or Repartition Streams logical operators.
Distribute Streams
: The Distribute Streams operator takes a single input stream of records
and produces multiple output streams. Each record from the input stream
appears in one of the output streams. Hashing is typically used to
decide to which output stream a particular input record belongs.
Gather Streams :
The Gather Streams operator consumes several input streams and produces
a single output stream of records by combining the input streams. If
the output is ordered, the ToolTip will contain an Order By item indicating the columns being ordered.
Repartition Streams :
The Repartition Streams operator consumes multiple streams and produces
multiple streams of records. Each record from an input stream is placed
into one output stream. If the output is ordered, the ToolTip contains
an Order By item indicating the columns being ordered.