After a database has been normalized to the
third form, database designers intentionally backtrack from
normalization to improve the performance of the system. This technique
of rolling back from normalization is called denormalization.
Denormalization allows you to keep redundant data in the system,
reducing the number of tables in the schema and reducing the number of
joins to retrieve data.
Tip
Duplicate data is more helpful when the data does
not change very much, such as in data warehouses. If the data changes
often, keeping all “copies” of the data in sync can create significant
performance overhead, including long transactions and excessive write
operations.
1. Denormalization Guidelines
When should you denormalize a database? Consider the following points:
Be sure you have a good overall
understanding of the logical design of the system. This knowledge helps
in determining how other parts of the application are going to be
affected when you change one part of the system.
Don’t
attempt to denormalize the entire database at once. Instead, focus on
the specific areas and queries that are accessed most frequently and
are suffering from performance problems.
Understand
the types of transactions and the volume of data associated with
specific areas of the application that are having performance problems.
You can resolve many such issues by tuning the queries without
denormalizing the tables.
Determine
whether you need virtual (computed) columns. Virtual columns can be
computed from other columns of the table. Although this violates third
normal form, computed columns can provide a decent compromise because
they do not actually store another exact copy of the data in the same
table.
Understand data integrity issues.
With more redundant data in the system, maintaining data integrity is
more difficult, and data modifications are slower.
Understand
storage techniques for the data. You may be able to improve performance
without denormalization by using RAID, SQL Server filegroups, and table
partitioning.
Determine the frequency
with which data changes. If data is changing too often, the cost of
maintaining data and referential integrity might outweigh the benefits
provided by redundant data.
Use the
performance tools that come with SQL Server (such as SQL Server
Profiler) to assess performance. These tools can help isolate
performance issues and give you possible targets for denormalization.
Tip
If you are experiencing severe performance problems, denormalization should not
be the first step you take to rectify the problem. You need to identify
specific issues that are causing performance problems. Usually, you
discover factors such as poorly written queries, poor index design,
inefficient application code, or poorly configured hardware. You should
try to fix these types of issues before taking steps to denormalize database tables.
2. Essential Denormalization Techniques
You can use various methods to denormalize a
database table and achieve desired performance goals. Some of the
useful techniques used for denormalization include the following:
Keeping redundant data and summary data
Using virtual columns
Performing horizontal data partitioning
Performing vertical data partitioning
Redundant Data
From an I/O standpoint, joins in a relational
database are inherently expensive. To avoid common joins, you can add
redundancy to a table by keeping exact copies of the data in multiple
tables. The following example demonstrates this point. This example
shows a three-table join to get the title of a book and the primary
author’s name:
select c.title,
a.au_lname,
a.au_fname
from authors a join titleauthor b on a.au_id = b.au_id
join titles c on b.title_id = c.title_id
where b.au_ord = 1
order by c.title
You could improve the performance of this query by adding the columns for the first and last names of the primary author to the titles table and storing the information in the titles
table directly. This would eliminate the joins altogether. Here is what
the revised query would look like if this denormalization technique
were implemented:
select title,
au_lname,
au_fname
from titles
order by title
As you can see, the au_lname and au_fname columns are now redundantly stored in two places: the titles table and authors
table. It is obvious that with more redundant data in the system,
maintaining referential integrity and data integrity is more difficult.
For example, if the author’s last name changed in the authors table, to preserve data integrity, you would also have to change the corresponding au_lname column value in the titles
table to reflect the correct value. You could use SQL Server triggers
to maintain data integrity, but you should recognize that update
performance could suffer dramatically. For this reason, it is best if
redundant data is limited to data columns whose values are relatively
static and are not modified often.
Computed Columns
A number of queries calculate aggregate values
derived from one or more columns of a table. Such computations can be
CPU intensive and can have an adverse impact on performance if they are
performed frequently. One of the techniques to handle such situations
is to create an additional column that stores the computed value. Such
columns are called virtual columns, or computed columns. Since SQL Server 7.0, computed columns have been natively supported. You can specify such columns in create table or alter table commands. The following example demonstrates the use of computed columns:
create table emp (
empid int not null primary key,
salary money not null,
bonus money not null default 0,
total_salary as ( salary+bonus )
)
go
insert emp (empid, salary, bonus) values (100, $150000.00, $15000)
go
select * from emp
go
empid salary bonus total_salary
----------- ------------- -------------------- ---------------
100 150000.0000 15000.0000 165000.0000
By default, virtual columns are not physically
stored in SQL Server tables. SQL Server internally maintains a column
property named iscomputed that can be viewed from the sys.columns
system view. It uses this column to determine whether a column is
computed. The value of the virtual column is calculated at the time the
query is run. All columns referenced
in the computed column expression must come from the table on which the
computed column is created. You can, however, reference a column from
another table by using a function as part of the computed column’s
expression. The function can contain a reference to another table, and
the computed column calls this function.
Since SQL Server 2000, computed columns have been
able to participate in joins to other tables, and they can be indexed.
Creating an index that contains a computed column creates a physical
copy of the computed column in the index tree. Whenever a base column
participating in the computed column changes, the index must also be
updated, which adds overhead and may possibly slow down update
performance.
In SQL Server 2008, you also have the option of
defining a computed column so that its value is physically stored. You
accomplish this with the ADD PERSISTED option, as shown in the following example:
--Alter the computed SetRate column to be PERSISTED
ALTER TABLE Sales.CurrencyRate
alter column SetRate ADD PERSISTED
SQL Server automatically updates the persisted
column values whenever one of the columns that the computed column
references is changed. Indexes can be created on these columns, and
they can be used just like nonpersisted columns. One advantage of using
a computed column that is persisted is that it has fewer restrictions
than a nonpersisted column. In particular, a persisted column can
contain an imprecise expression, which is not possible with a
nonpersisted column. Any float or real expressions are considered
imprecise. To ensure that you have a precise column you can use the COLUMNPROPERTY function and review the IsPrecise property to determine whether the computed column expression is precise.
Summary Data
Summary data is most helpful in a decision support
environment, to satisfy reporting requirements and calculate sums, row
counts, or other summary information and store it in a separate table.
You can create summary data in a number of ways:
Real-time—
Every time your base data is modified, you can recalculate the summary
data, using the base data as a source. This is typically done using
stored procedures or triggers.
Real-time incremental—
Every time your base data is modified, you can recalculate the summary
data, using the old summary value and the new data. This approach is
more complex than the real-time option, but it could save time if the
increments are relatively small compared to the entire dataset. This,
too, is typically done using stored procedures or triggers.
Delayed—
You can use a scheduled job or custom service application to
recalculate summary data on a regular basis. This is the recommended
method to use in an OLTP system to keep update performance optimal.
Horizontal Data Partitioning
As
tables grow larger, data access time also tends to increase. For
queries that need to perform table scans, the query time is
proportional to the number of rows in the table. Even when you have
proper indexes on such tables, access time slows as the depth of the
index trees increases. The solution is splitting the table into
multiple tables such that each table has the same table structure as
the original one but stores a different set of data. Figure 1
shows a billing table with 90 million records. You can split this table
into 12 monthly tables (all with the identical table structure) to
store billing records for each month.
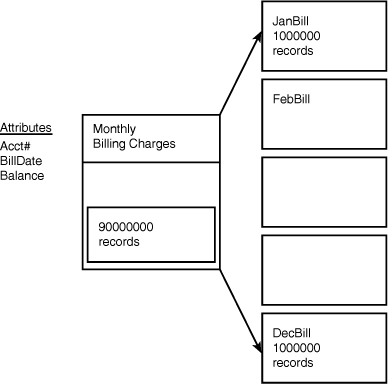
You should carefully weigh the options when
performing horizontal splitting. Although a query that needs data from
only a single month gets much faster, other queries that need a full
year’s worth of data become more complex. Also, queries that are
self-referencing do not benefit much from horizontal partitioning. For
example, the business logic might dictate that each time you add a new
billing record to the billing table, you need to check any outstanding
account balance for previous billing dates. In such cases, before you
do an insert in the current monthly billing table, you must check the
data for all the other months to find any outstanding balance.
Tip
Horizontal
splitting of data is useful where a subset of data might see more
activity than the rest of the data. For example, say that in a
healthcare provider setting, 98% of the patients are inpatients, and
only 2% are outpatients. In spite of the small percentage involved, the
system for outpatient records sees a lot of activity. In this scenario,
it makes sense to split the patient table into two tables—one for the
inpatients and one for the outpatients.
When splitting tables horizontally, you must perform
some analysis to determine the optimal way to split the table. You need
to find a logical dimension along which to split the data. The best
choice takes into account the way your users use your data. In the
example that involves splitting the data among 12 tables, date was
mentioned as the optimal split candidate. However, if the users often
did ad hoc queries against the billing table for a full year’s worth of
data, they would be unhappy with the choice to split that data among 12
different tables. Perhaps splitting based on a customer type or another
attribute would be more useful.
Note
You can use partitioned views to hide the horizontal
splitting of tables. The benefit of using partitioned views is that
multiple horizontally split tables appear to the end users and
applications as a single large table. When this is properly defined,
the optimizer automatically determines which tables in the partitioned
view need to be accessed, and it avoids searching all tables in the
view. The query runs as quickly as if it were run only against the
necessary tables directly.
In SQL Server 2008, you also have the option of
physically splitting the rows in a single table over more than one
partition. This feature, called partitioned tables,
utilizes a partitioning function that splits the data horizontally and
a partitioning scheme that assigns the horizontally partitioned data to
different filegroups. When a table is created, it references the
partitioned schema, which causes the rows of data to be physically
stored on different filegroups. No additional tables are needed, and
the table is still referenced with the original table name. The
horizontal partitioning happens at the physical storage level and is
transparent to the user.
Vertical Data Partitioning
As you know, a database in SQL Server consists of
8KB pages, and a row cannot span multiple pages. Therefore, the total
number of rows on a page depends on the width of the table. This means
the wider the table, the smaller the number of rows per page. You can
achieve significant performance gains by increasing the number of rows
per page, which in turn reduces the number of I/Os on the table.
Vertical splitting is a method of reducing the width of a table by
splitting the columns of the table into multiple tables. Usually, all
frequently used columns are kept in one table, and others are kept in
the other table. This way, more records can be accommodated per page,
fewer I/Os are generated, and more data can be cached into SQL Server
memory. Figure 2 illustrates a vertically partitioned table. The frequently accessed columns of the authors table are stored in the author_primary table, whereas less frequently used columns are stored in the author_secondary table.
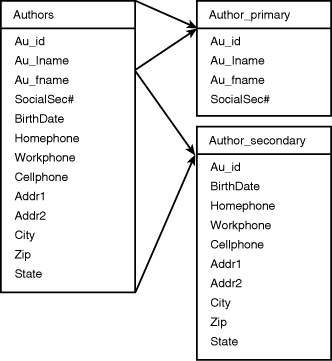
Tip
Make the decision to split data very carefully,
especially when the system is already in production. Changing the data
structure might have a system-wide impact on a large number of queries
that reference the old definition of the object. In such cases, to
minimize risks, you might want to use SQL Server views to hide the
vertical partitioning of data. Also, if you find that users and
developers are frequently joining between the vertically split tables
because they need to pull data together from the two tables, you might
want to reconsider the split point or the splitting of the table
itself. Doing frequent joins between split tables with smaller rows
requires more I/Os to retrieve the same data than if the data resided
in a single table with wider rows.
Performance Implications of Zero-to-One Relationships
Suppose
that one of the development managers in your company, Bob, approaches
you to discuss some database schema changes. He is one of several
managers whose groups all use the central User table in your database. Bob’s application makes use of about 5% of the users in the User
table. Bob has a requirement to track five yes/no/undecided flags
associated with those users. He would like you to add five
one-character columns to the User table to track this information. What do you tell Bob?
Bob has a classic zero-to-one problem. He has some
data he needs to track, but it applies to only a small subset of the
data in the table. You can approach this problem in one of three ways:
Option 1: Add the columns to the User table—In this case, 95% of your users will have NULL values in those columns, and the table will become wider for everybody.
Option 2: Create a new table with a vertical partition of the User table—The new table will contain the User primary key and Bob’s five flags. In this case, 95% of your users will still have NULL data in the new table, but the User
table is protected against these effects. Because other groups don’t
need to use the new partition table, this is a nice compromise.
Option 3: Create a new vertically partitioned table as in Option 2 but populate it only with rows that have at least one non-NULL
value for the columns in the new partition—This option is great for
database performance, and searches in the new table will be wonderfully
fast. The only drawback to this approach is that Bob’s developers will
have to add additional logic to their applications to determine whether
a row exists during updates. Bob’s folks will need to use an outer join
to the table to cover the possibility that a row doesn’t exist.
Depending on the goals of the project, any
one of these options can be appropriate. Option 1 is simple and is the
easiest to code for and understand. Option 2 is a good compromise
between performance and simplicity. Option 3 gives the best performance
in certain circumstances but impacts performance in certain other
situations and definitely requires more coding work to be done.