Replication
is the process by which data and database objects are distributed from
SQL Server to other database engines that reside across an enterprise;
this data can be distributed to other SQL Server databases or even
non–SQL Server databases such as Oracle and others. Replication can be
explained by using a publisher/subscriber/distributor metaphor. To
understand replication, you must understand and become familiar with the
basic concept of the publisher/distributor/subscriber metaphor. This
metaphor defines the different roles SQL Server can play in the
replication process. Each role provides functionality that aids in the
replication process:
Publisher—
In replication terminology, the publisher is the server that produces
the original data for the use of the replication process. The publisher
can produce many publications or sets of data to be distributed to other
subscribing machines. One publisher can produce data to be replicated
to many subscribers. Also, many publishers can produce data to be
distributed to just a single, central subscriber. The former is
implemented as a standard central publisher/distributor/subscriber
replication model, and the latter is referred to as central subscriber replication.
Distributor—
The distributor is the server that contains the distribution database,
data history, and transactions; as its name implies, it sends data to
subscribers. The distributor can be implemented on the same physical
server as the publisher or subscriber, although it doesn’t need to be.
It can reside on a separate server somewhere else in the world and be
connected via a network. The placement of the distributor and its
characteristics depend on the type of replication used.
Subscriber—
A subscriber, in SQL Server terms, is the server that receives
replicated data through the distributor. Subscribers can choose from the
publications available at the publisher and don’t necessarily need to
subscribe to them all.
Other
replication terminologies are also important to the process and fall in
line with the subscription metaphor. When a subscription is set up, a
publication made up of one or more articles is configured. Simply put,
articles are data structures made up of selected columns and/or rows
from a table. An article could also be an entire table, although it is
recommended that the content of an article be kept to just the minimum
amount of data needed for a particular implementation. One or more
articles are bundled into a publication to be used for replication.
Articles must be grouped into a publication before they can be
replicated. In short, a publication is a collection of one or more
articles and is capable of being replicated.
Replication Strategies
Replication, with
its many benefits, serves as a backbone for many businesses. Placing the
same data on multiple servers, with each server closer to the user’s
location, can reduce the use of bandwidth and provide the user with
faster update operations and retrieval of data. Without replication,
businesses would be incapable of carrying out robust branch operations
around the globe. Database administrators favor replication for the
following reasons:
In using
replication, businesses are capable of having data copied from server to
server in a multisite enterprise. It provides flexibility and more
efficient use of networking resources.
Replication allows for greater concurrent use of data; that is, it allows more people to work with the data at the same time.
Copies of the database can be distributed, bringing data closer to the end user and providing a form of load balancing.
Replication
is perfect for traveling salespeople and roaming disconnected users. It
enables mobile users who work on laptops to be updated with current
database information when they connect and to upload data to a central
server.
Replication
techniques can be applied to three replication models, as well as
several different physical models. The physical aspects and models have
no direct correlation. A replication model supplies the functionality,
whereas the physical model shows the placement and roles of individual
servers.
Merge, snapshot, and
transactional replication all involve essentially the same basic
elements to begin with. However, each model has idiosyncrasies of its
own that require some thought during implementation design.
You
can compress or save to a CD the initial snapshot that begins the
replication process in order to offload some of the necessary
communications. Doing so makes more efficient use of network bandwidth,
especially in slow-link or dial-up environments.
You can set up a subscription as either a push subscription or a pull subscription:
Push subscription— A publisher initiates a push subscription and provides the basis for scheduling the replication process.
Pull subscription— The subscriber initiates a pull subscription and provides the basis and timing on which data is to be obtained.
In either case, whoever initiates a subscription selects the appropriate articles to be transmitted.
Replication can be set up in
various ways. The different scenarios in which replication is set up
each provide specific benefits and have unique characteristics. SQL
Server can serve as the publisher, subscriber, or distributor. The
individual roles can all be set up on a single machine, although in most
implementations, there is at least a separation between a
publisher/distributor and the subscribing machine(s). In some other
scenarios, the subscriber of the data from one machine may republish the
data to still other subscribers. The possibilities are endless. You can
choose to implement any of the following common scenarios, which cover
the basics of a physical replication model. In real-world scenarios,
however, the actual physical model used could have any combination of
these elements, based on a business’s individual needs:
Central publisher and multiple subscribers
Multiple publishers and multiple subscribers
Multiple publishers and a single subscriber
Single publisher and a remote distributor
Using a Central Publisher and Multiple Subscribers
In
replication using a central publisher and multiple subscribers, the data
originates at the publishing server, and that original data is sent to
multiple subscribers via the distributor. Depending on the form of
replication used, changes to the data at the destination servers can
enable updates to be propagated back to the publisher and other
subscribers, or it can be treated as read-only data, in which updates
occur only at the publisher. This type of scenario is typically used
when a company has a master catalog at the headquarters and has many
different subscribers located elsewhere.
An advantage of this
configuration is that multiple copies of the data from a central server
are available for user processing on multiple machines. Data can be
distributed to the locations where it is needed. With this form of
replication, data can
be brought closer to the user, and this can reduce the load on a single
server. Expensive bandwidth can also be utilized in an improved manner.
Using Multiple Publishers and Multiple Subscribers
In replication
using multiple publishers and multiple subscribers, every server
publishes a particular set of rows that relate to it and subscribes to
the publications that all the other servers are publishing so that each
of them can receive data and send data. This form of replication is
typically used in a distributed warehouse environment with inventory
spread out among different locations, and it can also be used in any
other situation in which the data being held at each location-specific
server needs to be delivered to the other servers, so that each location
has a complete set of data.
For replication
using multiple publishers and multiple subscribers, the correct database
design is crucial to having each server publish and subscribe to the
correct information. The table structure for the data involved in the
publication is usually implemented with a compound primary key or unique
index, although it is possible to use an identity or another algorithm
that enables each location to be uniquely identified within the entire
table. One portion of the key is an identifier for the location, and the
second element is the data identifier.
Using Multiple Publishers and a Single Subscriber
In replication
using multiple publishers and a single subscriber, a server subscribes
to publications on some or all of a number of other publishing servers.
This is needed when all data from all locations is required to be sent
to only one site, possibly the headquarters. Data can be collected from
widely dispersed areas, and the central location, the subscriber, would
end up with a master database from all the publishers combined.
Using a Single Publisher and a Remote Distributor
Replication does not
require a distributor residing on the same server or even within close
proximity to the publisher. Instead, the machine handling the
distribution can be implemented as a totally separate segment. This is
practical when you need to free the publishing server from having to
perform the distribution task and minimize costs that can be incurred
over long-distance or overseas network connections. Data can also be
replicated faster and delivered to many subscribers at a much lower
cost, while minimizing the load on the publisher. In situations in which
the connection between the publisher and the subscriber is over a slow
link or over high-cost connections, a remote distributor should be used
to lower the cost and increase data transfer rates.
The individual
roles of each server are implemented in all types of replication
scenarios; the physical configuration does not dictate the type of
replication used. The next section examines the types of replication and
their implementation.
Types of Replication
Each replication
model provides different capabilities for distributing data and
database objects. There are many considerations for selecting a
replication type and determining whether replication is a suitable
technique for data distribution. The many considerations to determine
the suitability of each of the models include transactional consistency,
the subscriber’s capability or lack of capability to update data,
latency, administration, site autonomy, performance, security, the
update schedule, and the available data sources. Each of these is
defined by the replication configuration, and they are discussed through
the next several sections.
Other data distribution
techniques that don’t involve replication can offer a different set of
features but may not provide the flexibility that replication offers. To
determine which replication type is best suited to your needs, you need
to consider three primary factors: site autonomy, transactional
consistency, and latency. These three considerations are illustrated in Figure 1, which also compares and contrasts data distribution techniques.
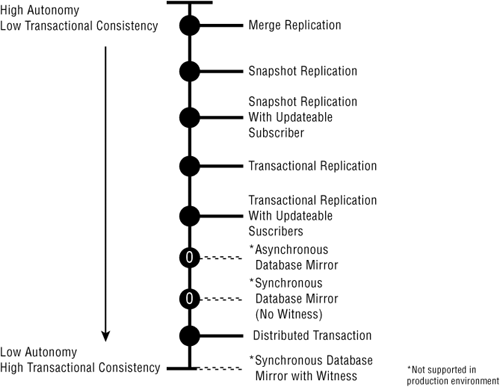
When you are in the
position of selecting a data distribution technique, you need to answer
three questions: How much site independence is required in processing
changes to the data (autonomy)? How consistent does data need to remain
after changes are made (consistency)? How soon does data need to agree at
all replication locations (latency)? The answers to these questions, as
described in the following sections, determine the approach you should
use.
Site Autonomy in Replication
Site autonomy measures
the effect of a site’s operation on another site. A site that has full
autonomy is completely independent of all other sites, which means it
can function without even being connected to any other site. High site
autonomy can be achieved in SQL Server replication where it would not be
possible using other data distribution techniques. Not all replication
configurations achieve autonomy; such high site autonomy can be seen
best with merge replication.
Site
autonomy directly affects transactional consistency. To achieve an
environment that is autonomous and has a high degree of transactional
consistency, the data definition must provide a mechanism to
differentiate one site from the other. A compound primary key, for
example, in a “central subscriber” or “multiple publisher, multiple
subscriber” scenario, allows autonomy while achieving transactional
consistency. If an implementation enables each site to update the same
data, it will always have some degree of transaction inconsistency or at
least a delay before consistency is achieved.
Transactional Consistency in Replication
Transactional
consistency is a measure of changes made to data, specifically changes
that remain in place without being rolled back. Changes can get rolled
back due to conflicts, and this affects user changes and other user
activities. In replication, you have multiple distinct copies of your
data, and if you allow updates to each copy, it is possible for
different copies of a piece of data to be changed differently. If this
situation is allowed, as is the case in some forms of replication, you
have imperfect (low) transactional consistency. If you prevent two
copies from changing independently, as is the case with a distributed
transaction, you have the highest level of transactional consistency.
In a distributed
transaction, the application and the controlling server work together to
control updates to multiple sites. Two-phase commits implemented in
some forms of replication also help. The two phases used are preparation
and committal. Each server is prepared for the update to take place,
and when all sites are ready, the change is committed at the same time
on all servers. When all sites have implemented the change,
transactional consistency is restored.
Latency in Replication
Latency
can be thought of as how long data in the subscriber has to wait before
being updated from the copy of the data on the publisher. Several
factors contribute to latency, but it is essentially the length of time
it takes changes to travel from the publisher to the distributor and
then from the distributor to the publisher. If there is no need for the
data to be identical, at the same time, in all publishers and
subscribers, the latency resident in a replication strategy will not
negatively affect an application.
In
SQL Server 2005, you can use the Tracer Tokens tab of the Replication
Monitor to monitor latency. Tracer tokens, which are new to SQL Server,
allow you to validate connections and to measure latency. A token is a
small amount of data that is written to the transaction log of the
publication database as though it were a typical transaction. It is then
sent through the system for measurement.
The two-phase
commit that SQL Server implements through the use of immediate updating
can minimize latency on updates coming from the subscriber, but it has
no effect on updates sent from the publisher. A number of factors can
affect latency, including the workload on the publisher and distributor,
the speed and congestion of the network, and the size of the updates
being transported.
Elements of Replication
Each type of replication
offers advantages and disadvantages. You must select the type based on
the requirements of the business application. Three types of
replication—snapshot, transactional, and merge—move data by using
different principles.
Using Snapshot Replication
Snapshot
replication distributes data and database objects by copying the entire
contents of the published items via the distributor and passing them on
to the subscriber exactly as they appear at a specific moment in time,
without monitoring updates. A snapshot is stored on the distributor,
which encapsulates data of published tables and database objects; this
snapshot is then taken to the subscriber database via the distribution
agent.
Snapshot
replication is advantageous when replicated data is infrequently updated
and modified. A snapshot strategy is preferable over others when data
is to be updated in a batch. This does not mean that only a small amount
of data is updated, but rather that data is updated in large quantities
at distant intervals. Because data is replicated at a specific point in
time and not replicated frequently, this type of replication is good
for online catalogs, price lists, and the like, in which the decision to
implement replication is independent of how recent data is.
Snapshot replication offers
a high level of site autonomy. It also offers a great degree of
transactional consistency because transactions are enforced at the
publisher. Transactional consistency also depends on whether you are
allowing updating subscribers and what type (immediate or queued) you
are allowing.
Using Transactional Replication
Transactional
replication involves moving transactions captured from the transaction
log of the publishing server database and applying them to the
subscriber’s database. The transactional replication process monitors
data changes made on the publisher.
Transactional
replication captures incremental modifications that were made to data in
the published table. The committed transactions do not directly change
the data on the subscriber but are instead stored on the distributor.
These transactions held in distribution tables on the distributor are
sent to the subscriber. Because the transactions on the distributor are
stored in an orderly fashion, each subscriber acquires data in the same
order as is in the publisher.
When replicating a
publication by using transactional replication, you can choose to
replicate an entire table or just part of a table, using a method
referred to as filtering.
You can also select all stored procedures on the database or just
certain ones that are to be replicated as articles within the
publication. Replication of stored procedures ensures that the
definitions they provide are in each setting where the data is to be
found. Processes that are defined by the stored procedures can then be
run at the subscriber. Because the procedures are being replicated, any
changes to these procedures are also replicated. Replication of a stored
procedure makes the procedure available for execution on the local
server.
Using Merge Replication
Merge replication is
the process of transferring data from the publisher to the subscriber,
which enables the publisher and subscriber to update data while they are
connected or disconnected and then merge the updates after they are
both connected; this provides virtual independence. Merge replication
therefore allows the most flexibility and adds the most autonomy to the
replication process. Merge replication is also the most complex
replication because it enables the publisher and subscriber to work
independently. The publisher and subscriber can combine their results at
any certain time, and they can also combine or merge their updated
results.
The Snapshot Agent and
the Merge Agent help in carrying out the process of merge replication.
The Snapshot Agent is used for the initial synchronization of the
databases. The Merge Agent then applies the snapshot; after that, the
job of the Merge Agent is to increment the data changes and resolve any
conflicts according to the rules configured.
Conflicts are
likely to occur with merge replication. Conflicts occur when more than
one site updates the same record. This happens when two users
concurrently update or modify the same record with different values.
When a conflict occurs,
SQL Server has to choose a single value to use. It resolves the
conflict based on either the site priority on the database site or a
custom conflict resolver, which can be CLR based in any language, in SQL
Server 2005.