Database server failures can be costly in production
environments. A high-availability solution is a solution that minimizes
failures and downtime. In a good solution, the effects of hardware or
software failures are minimal, if they exist at all. The idea is to
maintain the availability of the server and its objects, allowing
applications to interact without fail. Downtime needs to be minimized,
eliminated, or scheduled for times when applications do not need access
to the data.
You can do many things
to minimize or eliminate downtime and to prepare a disaster recovery
plan in the event that something does occur. You start with backups and
scheduled maintenance.
In some cases, you can have
a single, standalone server. Even with backup, if something goes wrong,
you have to restore from a backup to get back up and running again. A
solution in which every minute of downtime costs hundreds of dollars is
not a good solution.
In other cases, you can implement one of the secondary server solutions, often called warm backups.
Through log shipping or replication, you can achieve a better
percentage of uptime, at a reasonable cost. In these scenarios, a
secondary server is constantly being refreshed with the latest
information. If something goes wrong with the primary server, it is
simply a matter of switching processing over to the secondary server,
which requires much less loss of processing and data access time than
does restoring from backup.
You can also use
more costly solutions, such as using redundant hardware and simultaneous
update solutions (for example, database mirroring, failover
clustering). With several solutions, you update data simultaneously
within multiple database engines. If one system fails, the other can
take over without missing a beat.
Generally,
at the lowest end of the spectrum, you have low cost but high risk and
essentially no high-availability solution in place. As you move up to
the high-availability solutions, you have a low cost with some risk
(loss due to failure) and a degree of latency (the amount of time before
data agrees in two locations). At the higher end, you achieve lower
risk and minimal latency, but at higher cost.
Implementing Log Shipping
Log shipping is a
reasonably low-cost solution for increasing availability. Log shipping
operates at the database level, and it provides for redundant storage of
data in a multiple-server environment. With log shipping, one or more
standby databases operate as warm backups. These secondary databases are
referred to as warm copies
of the primary database. The primary database is the only copy that can
be updated, and the secondary database can be set up as a read-only
database to offload query-related processing from the primary server.
The secondary database can also be set up solely as a standby, offline
copy of the primary database.
You initiate a secondary database by restoring a full backup of the
primary database without recovery. You can do this ahead of time or as
part of the log shipping setup. After you restore the full backup with no
recovery, the secondary database reflects the standby status in
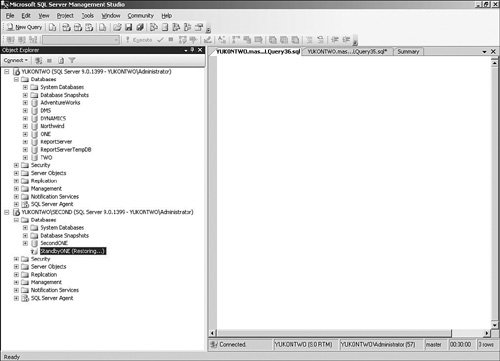
Management Studio. In Figure 1, the ONE database on the default instance of YUKONTWO has been fully backed up, and that backup has been restored onto the StandbyONE database on the YUKONTWO\SECOND instance of the server.
A log shipping
configuration includes two or more instances of SQL Server. One instance
holds the primary database, and one or more instances hold copies of
the database as secondary databases. You also can optionally configure a
monitor server. You control the process by creating and executing jobs
at the appropriate servers.
The primary server
performs log backups at regular intervals. A single job is created on
the server to perform these backups on schedule and stores the backups
on a network share that is accessible to both the primary and secondary
machines. The default is to perform the operation every 15 minutes, but
you can alter this timing if you want more or less frequency. The timing
here and the timing of the associated jobs on the secondary server
determine the actual latency.
Each secondary server
utilizes two jobs to perform regular updates of its secondary database
from log backups created on the primary server. The first job performs a
copy of the log backup to a destination folder (usually located on the
secondary server). The second job controls the restore operations. You
can have the restore use no recovery to keep the database offline or use
the standby option to cause the server to become read-only, for
reporting purposes.
The monitoring
instance executes one job on a regular basis to identify and alert an
operator if the log shipping is not operating as it is designed to
operate. Log shipping has no automated failover to the secondary
instance. This brings with it the risk of downtime in the event of
failure. There is also an associated risk of data loss for the interval
between log backups if there is a failure in the logging hardware.
Before failover can occur, the secondary databases must be brought fully
up-to-date manually. Secondary databases also have limited availability
during restores, so they might be unavailable as reporting sources
during restores.
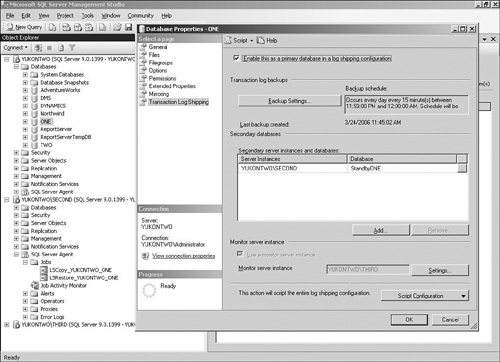
You can perform the
complete setup of log shipping, including the configuration of all
tasks, by using Management Studio. To do so, you right-click the primary
database and select Tasks and then Ship Transaction Logs. Figure 2
shows an example of this configuration. In this example, all three
instances are running on the same physical machine, which is an unlikely
scenario in a production environment and in fact would defeat the
purpose of attempting to provide a high-availability solution.
You can use log
shipping alone or as a supplement to database mirroring. When these
solutions are used together, the current principal database of the
database mirroring configuration is also the current primary database of
the log shipping configuration.
Using Database Mirroring
Microsoft support
policies do not apply to the database mirroring feature in SQL Server
2005. Database mirroring is currently disabled by default, but may be
enabled for evaluation purposes only by using trace flag 1400 as a
startup parameter. (For more information about trace flags, see Trace
Flags (Transact-SQL).) Database mirroring should not be used in
production environments, and Microsoft support services will not support
databases or applications that use database mirroring. Database
mirroring documentation is included in SQL Server 2005 for evaluation
purposes only, and the Documentation Policy for SQL Server 2005 Support
and Upgrade does not apply to the database mirroring documentation.
Enabling Trace Flags in a Test Environment
You can enable trace flag 1400 to get a look into database mirroring; to do so, you have two choices:
You can stop the service and run sqlsrvr.exe from the command prompt by using the following:
sqlservr
-d"C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Data\master.mdf"
-T1400
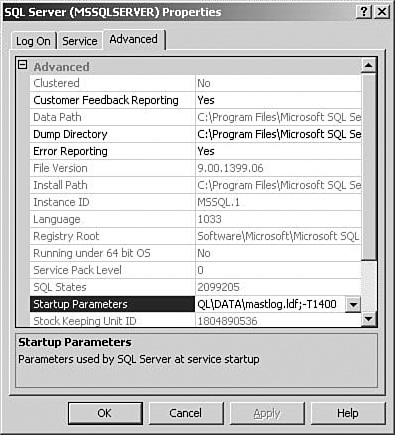
You can add the -T1400
flag as a startup option in SQL Server Configuration Manager. You must
separate each startup option from the previous option with a semicolon,
as shown in Figure 3.
SQL Server database
mirroring is implemented on a per-database basis to increase
availability. You must have the database set to the full recovery model,
and you cannot mirror the master, msdb, tempdb, or model databases.
Mirroring maintains two
copies of a database. Each copy is held on a separate instance of SQL
Server. Optionally, a third instance can act as a mirroring witness to
observe activity and to alert and/or fail over if problems occur. In
database mirroring, the witness server is an instance of SQL Server that
monitors the status of the principal and mirror servers. The witness,
by default, can initiate automatic failover if the principal server
fails. Typically, each instance resides on a separate machine, but it is
possible to configure all three instances on the same computer.
The
principal database is the updatable version of the database, and the
mirror copy duplicates the activity of the principal. The two instances
communicate over database mirroring endpoints that control the mirroring
sessions. If a witness is used, a third endpoint is created on that
instance for communication purposes.
You begin mirroring similar
to the way you begin log shipping: You perform a full backup of the
principal database and restore the backup onto the mirror instance with
the no recovery option. You then proceed to perform log backups of the
principal database, having them restored onto the mirror copy. The
applications can be performed synchronously or asynchronously. If you
are configuring as synchronous with automatic failover, a witness
instance is mandatory. If the configuration is synchronous without
failover or asynchronous, the witness is optional.
A synchronous
configuration commits changes to both servers simultaneously. The
asynchronous configuration first commits the changes on the principal
database and then transfers the changes to the mirror copy. If automatic
failover is configured, the witness controls the failover to the mirror
if the principal server becomes unavailable.
Because these
configurations are not currently supported in a production environment,
the only true failover configuration available in a SQL Server
environment is failover clustering.
Using Failover Clustering
Failover clustering
provides high-availability support for SQL Server. In the event of a
failure, SQL Server can maintain business operations through the use of
multiple instances of the database engine. You can configure the
environment such that one node of a cluster can fail over to another
node in the cluster during any failure.
A failover cluster is set up
as a series of one or more nodes. Each node is a server in its own
right. The nodes operate with two or more shared disks. The shared disks
maintain the resources that the node set accesses. This disk
configuration is known as the resource group or grouping.
Collectively, the entire configuration makes up a single virtual
server. Applications communicate with a singular machine over a single
IP address.
A
SQL Server virtual server appears as if it were a single computer. This
allows applications to perform their database access without the need
for reconfiguration if something happens to one of the nodes in the
cluster. A failover cluster is a hardware configuration that requires
special computer hardware. Of course, this special hardware comes at a
cost, making a failover cluster implementation much more costly than
other forms of high availability. If you lack the budget or hardware to
implement this strategy, replication may be a better solution.