The final component that can be scaled out
with regards to search is crawler. In the topology search application
page, it is broken into two items:
Crawl Database
Crawl Component
The Crawl Server comprises of the crawl component
that is associated with a crawl database. Each crawl database has one
or more crawl components (crawlers) to index its content. It is
typically scaled out for redundancy purposes or to increase the speed
of the crawl.
The crawler crawls the content sources and creates
the index partition(s). Then it sends the created partition(s) to the
query server(s). It does not hold the index partition. It writes
details about the crawl into the crawl database. It is stateless in
that it does not retain information itself.
Getting ready
You must have farm-level administrative permissions to the Central Administration site.
How to do it...
Open the Central Administration site and click Application Management.
The third section is Service Applications. Under this section, click Manage service applications.
Find the Search Service Application
option and click on it (this is the name SharePoint assigns by default
if not modified when creating the Search Service). The ribbon will
light up. Click Manage.
Under the Search Application Topology section, there is a button called Modify; click this button.
The Search Service Topology page appears. Click the drop-down list named New and select Crawl Database.
The pop-up screen that appears is almost exactly like the property database pop up seen in the preceding recipe.
Fill in the following elements:
Enter the name of a database server.
Enter a name for the crawl database.
Select the Windows authentication option under Database authentication section.
If you have the name of a Failover Server, enter it in the appropriate textbox.
There is one more item in the pop-up that needs to be addressed. As shown in the next screen, do not check the Dedicate this crawl... box. It will be addressed in the Adding a host distribution rule recipe.

Click OK.
The Search Service Topology Application page will be shown again. To commit the changes you have done in the previous screen, click the Apply Topology Changes button.
Click the drop-down list named New and select Crawl Component.
The following pop-up screen appears:
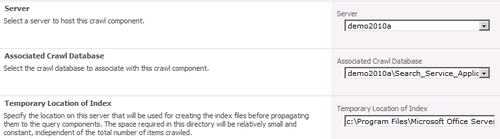
Perform the following steps:
Choose a server from the drop-down list, on which to host the crawl component.
Choose the associated crawl database from the drop-down list.
Specify a location for the index by entering the value in the Temporary Location of Index textbox.
Click OK.
The Search Service Topology Application page will again be shown. To commit the changes you have done on the screen, click the Apply Topology Changes button.
How it works...
The creation of the crawl database is similar to the
property database. A new database is added to the farm and can be seen
physically via SQL Management Studio.
The only additional item is using host distribution rules, which will be covered in the Adding a host distribution rule recipe.
The crawl component, which is created after the
database, creates a temporary index that gets stored on the Crawl
Server. This index is eventually propagated and overwritten.
The crawl content and the data such as the location
of the content source are saved in the crawl database. It is the
crawler's job to propagate partition-indexed data to the query servers.
The crawler is truly a stateless object.
There's more...
Everything done using the UI can be scripted via PowerShell in order to automate the procedure.
Use the following command to create a new crawl database:
New-SPEnterpriseSearchCrawlDatabase
Use the following command to create a new crawl component:
New-SPEnterpriseSearchCrawlComponent
To see examples of these commands, type get-help <command> -examples in the PowerShell management shell.
More info
A crawl topology can contain multiple crawl
components. By mapping multiple crawl components to a single crawl
database, performance will increase and fault tolerance is achieved.
If one of the crawl components crashes, the remaining crawl components step in and perform the indexing.
If the crawler database server fails and
you have specified a failover database server, SharePoint will
automatically switch over to use it. However, this requires your SQL
Servers to use synchronous mirroring. Asynchronous mirroring is not
supported in this case.