SharePoint 2010 continues to support the high-availability
options included in SharePoint Server 2007 and also introduces new
options for increasing high availability of your SharePoint information.
In this section, you
will learn how SharePoint 2010 leverages redundancy to increase high
availability by using some of the most popular underlying SQL Server
technologies, including failover clustering, database
mirroring, log shipping, and read-only databases. The following
high-availability options are supported in SharePoint 2010.
SQL database mirroring, both asynchronous and synchronous
SQL Server log shipping
Combined database mirroring and log shipping
Read-only databases
SQL Server failover clustering
1. SQL Database Mirroring
SharePoint 2010 leverages SQL
Server’s high-availability technologies, such as database mirroring, to
achieve high-availability architecture for SharePoint. In SharePoint
2010, you can specify a failover database for each content database
using SharePoint Central Administration, Windows PowerShell, or STSADM.
Database mirroring maintains
two copies of a single database that must reside on different SQL Server
instances. Typically, these SQL instances reside on different
computers. The SQL Server instance hosting the database that clients
access is called the principal server. The second SQL Server instance, called the mirror server,
contains a copy of the database on the principal server. The mirror
server can be configured to act as a warm standby server and improve
performance but not provide high availability, or it can provide high
availability, but with a slight performance degradation. A mirroring
session can only have one principal server and one mirror server. There
are two types of mirrored sessions that can be configured; these are
asynchronous and synchronous.
1.1. Asynchronous Database Mirroring
When SQL Server mirroring is
configured in asynchronous mode, it is operating in high-performance
mode. Under asynchronous operations, the transactions commit without
waiting for the mirror server to write the log to disk, which improves
performance. The mirror server tries to keep up with the log records
sent by the principal server. However, the mirror database may
experience some latency behind the principal database. When the
principal server experiences a problem, the mirror server is only
available as a warm standby database server, and there is a chance of
some data loss because all transactions haven’t been written to the
mirror server in asynchronous mode.
1.2. Synchronous Database Mirroring
When SQL Server mirroring
is configured in synchronous mode, it is operating in high-safety mode,
which provides high availability. All the committed transactions from
the principal database server are guaranteed to be written to disk on
the mirror server. This process begins by performing an initial
synchronization from the principal database to the mirror database. To
ensure that the data on the two servers remains consistent, the active
log from the principal database server is sent to the mirrored database
server and applied to that server with minimal latency between the
changes made on the principal database and mirrored database. This
provides rapid failover without loss of data from committed transactions
The name of the database
on both the mirror and principal server must be exactly the same for
synchronous database mirroring to occur properly, and you must use Full
Recovery mode on the databases.
To implement automatic
failover, the session must have a third SQL server instance, the
witness, which ideally resides on a third computer and simply monitors
the principal server for connectivity. If the witness server discovers
that the principal database server is unavailable for more than 15
seconds (by default), and there is still connectivity between the
witness and mirror, then the mirror database server performs an
automatic failover.
Mirroring has advantages over log
shipping, since it is a function of the SQL Server engine and can
provide synchronous replication. Database mirroring is more expensive
and complex, since it requires three SQL Server instances when
configured in synchronous mode.
2. SQL Server Transaction Log Shipping
SQL Server log shipping
allows you to automatically send transaction log backups from a primary
server database, often your production server, to one or more secondary
database servers. These secondary servers can be used as hot standby
servers as well as read-only content servers for generating reports. The
primary server database transaction log backups are automatically
shipped to each of your secondary database servers. Optionally, you can
configure a third server, called a monitor server,
that is responsible for monitoring the history and status of the backup
and restore operations, and if configured to do so, will generate an
alert if either of these operations fail.
Log shipping involves the following three jobs.
The primary server SQL Server agent backs up the transaction log of primary database.
The SQL Server Agent on the secondary SQL server initiates a copy of the primary server transaction log.
The Agent on the secondary server applies the copied transaction log to the associated secondary server database.
If you are log shipping
to multiple standby servers from one primary server, steps 2 and 3 will
be repeated multiple times. The schedule for this process will
determine how current the secondary database server will be in the event
that you lose your primary database server.
The following list is a good starting point to
understand the basic elements of the procedure.
Use the same domain and accounts for all like processes (farm, IIS Processes, SQL SA account).
Use the same version (including updates) of SQL Server on both farms.
Document content database to Web application mappings.
Create the failover farm using a second SQL server (not just a second instance).
Use identical, corresponding content database names when creating Web applications on the second farm.
Configure a monitor server to track the details of the log shipping.
Use full or bulk-logged recovery model of databases on primary server.
Do not log ship Config or Central Administration databases.
Ship logs to a second SQL Server and verify their integrity.
Take the primary farm offline to test.
Bring the failover farm content databases online.
Bring the failover farm online.
Browse
using a different namespace, change the Domain Name System (DNS), or
purchase third-party software that will handle the redirection to the
new server.
Use the same TCP port for both Central Administration Web applications for ease of configuration.
Transaction
log shipping on a single LAN can work quite well to provide a failover
farm in the event of a catastrophic hardware failure. The downside to
transaction log shipping is the manual intervention required on the
failover server, since the databases will be in recovery mode and must
be brought online manually. Remember to change any settings in your DNS
servers to publish the new farm’s IP address, or simply educate your
users about the second namespace in the event of a disaster on your
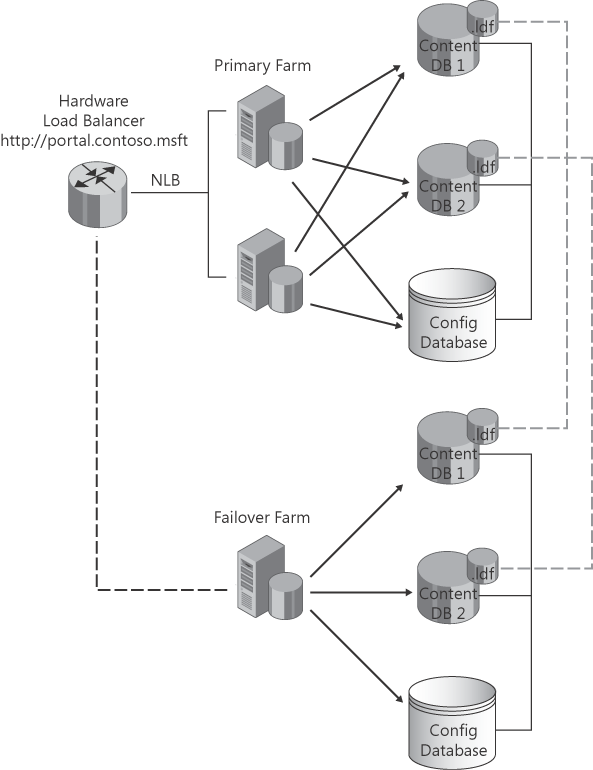
primary server. Figure 1 is an example of log shipping configuration in which both farms are located at the same geographical location.
3. Combining Database Mirroring and Log Shipping
Your principal database in a
mirrored configuration can also act as the primary database in a log
shipping configuration, or vice versa. This configuration allows you to
use the database mirroring session running in either synchronous or
asynchronous mode.
Although it is not
required, you typically want to configure the mirrored session first,
then your log shipping. Your mirrored principal database is configured
as the log shipping primary database (becoming a principal/primary
database), then one or more secondary server databases are configured.
Furthermore, the mirror database is configured as a log shipping primary
database (becoming a mirror/primary database).
For true high availability,
your log shipping secondary databases should be on different servers
than either the principal/primary server or the mirror/primary server.
Note:
When using SQL
Server transaction log shipping or database mirroring, it is important
to remember that all errors, such as those caused by file corruption or
incorrect data modifications, will be replicated from the primary farm
to the failover farm.
4. SQL Snapshots
SharePoint 2010 allows full use of native SQL Server database
snapshots. You can create, delete, and restore snapshots from within
SQL Server or by using Windows PowerShell. After you create the
snapshots, you can access them using STSADM or Windows PowerShell
command-line tools.
SQL Server database snapshots
are mechanisms that provide a read-only copy of your data that allows
you to roll back to the data point in time when the snapshot was made,
using an unattached content database or a content database snapshot. The
SQL Server snapshot of the data made before it was modified stores the
unmodified content in a snapshot database. You can then use that
database to roll back to the unmodified data.
5. SQL Server Failover Clustering
SQL Server failover
clustering provides high availability for SQL Server databases accessed
by SharePoint 2010. Most medium- to large-scale SharePoint 2010 farms
require a SQL Server cluster for fault tolerance. The basic two-server
(often referred to as nodes) Active/Passive cluster configuration shown in Figure 2
provides fault tolerance, but it does not improve performance. This
configuration is the easiest one to implement and provides high
availability of your SQL Server databases.
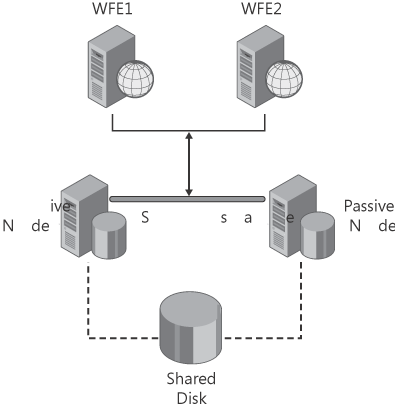
From within SharePoint, the
failover cluster instance appears as a single computer, but it provides
functionality that allows it to automatically roll over from the active
server to the passive server if the active server becomes unavailable.
This failover can take several seconds to several hours, depending on
the size of your transaction logs. Frequently truncating your
transaction logs increases SQL Server CPU and disk usage, and it also
can reduce your chances of recovering SQL Server data after a hardware
failure, but it does reduce the time required to failover to the passive
node from the active node.
The
failover cluster is a combination of one or more nodes and two or more
shared disks. SharePoint 2010 references the cluster as a whole,
providing a seamless automatic failover from the perspective of
SharePoint, with little or no interruption or data loss.