1. Problem
1.1. Context
Detecting faults in your software should be done as
early as possible during the development process since it can be over 10
times cheaper to detect them in the early stages of development
compared to finding them once your product has shipped .
1.2. Summary
You want to reduce the number of defects in
your software and so improve the experience for the end user by, for
example, avoiding loss of their privacy, corruption of their data, and
security vulnerabilities.
You want to reduce the effort associated with debugging and fixing defects.
You want to improve the maintainability of your software by making it easier to add new features safely.
1.3. Description
The problem we're focusing on here is how to detect
faults in our software since a common issue when developing software of
any complexity is programmer error. These mistakes manifest themselves
as defects, some of which will be very apparent while developing a
component; others are much more subtle and therefore long-lived and
insidious. Although they are all faults, there is a key difference
between defects found during the production of a system by its
developers and those discovered by end users of the software.
Finding defects during the development of a system has significantly less cost
than when they are found after the system has been deployed. Therefore a
lot of programming effort should go into producing code that is
functionally correct and as error free as possible; however, the effort
required to reach perfection steadily increases.
While simple, small, standalone programs can be debugged relatively
trivially, discovering the root cause of a defect in larger, more
complex systems can prove very time-intensive. The reason for this
general trend is that there is a greater number of components in larger
systems, with an exponentially greater possible number of interactions
between them. This is one reason why software engineers are encouraged
to abstract, encapsulate and modularize their designs, since it reduces
the number of these interactions (as promoted by patterns such as Proxy
and Façade as described in [Gamma et al., 1994]).
The root cause for a defect can be hard to track down in any system:
It may be that the defect doesn't occur in a
development environment and it is only out in the field where the issue
is first discovered. This may be for a number of reasons, such as race
conditions caused by event-driven programming or simply because there
weren't enough tests written.
The design of the software may not be well understood by the developer investigating a defect.
The
more complex a system becomes, the more likely it is that the defect
symptom manifests itself in a 'distant' component in which there is no
obvious connection between the observed issue and the root cause of the
defect.
Such defects can have a significant maintenance cost
associated with them. Notably they will be found later in the software
lifecycle and will take longer to fix.
For software based on Symbian OS, reducing the
occurrence of faults is especially important when compared to desktop
(or even enterprise) systems. Issuing software updates (or patches) is a
common practice for desktop PCs that are permanently connected to the
Internet, with large amounts of available storage and bandwidth.
Patching software on a mobile device is less widespread, more complex
and can be more expensive due to data transmission costs. Reducing the
need to issue incremental updates to correct defects is of great value.
Less tangibly, there is also the user's expectation of reliability.
Given the current climate, end users are used to their PCs containing
defects and the requirement for anti-virus software, firewalls, and
continual patching is accepted. For Symbian OS though, devices are
generally expected to work, out of the box, and be always available. To
meet these expectations, removal of defects early in the development
cycle is essential.
1.4. Example
An example of a complex software component would be a
multiplexing protocol. For such a component there are three different
viewpoints from which to observe its software requirements:
API calls from clients on top of the stack –
these direct the protocol to perform tasks, such as who to connect to
and to send or receive data.
Internal
state – the constructs used by the software to satisfy API requests
from clients while respecting the protocol specification for
communicating with remote devices.
Protocol
messages from a remote device – data and control packets sent as part
of the communication protocol both to and from peers.
An example of such a protocol is the Bluetooth Audio
Video Distribution Transport protocol (AVDTP) which has a specified
interface known as the Generic Audio Video Distribution Profile (GAVDP).
A GAVDP client will have a number of requirements on
the API. These requirements will normally be mapped onto the features
laid out in the GAVDP specification published by the Bluetooth Special
Interest Group (SIG) which includes connecting to a remote device,
discovering remote audio–video (AV) stream endpoints, determining the
capabilities of an endpoint, as well as configuring and controlling a
logical AV stream. This is in addition to the fundamental requirement of
sending and receiving the AV data associated with an AV stream.
The protocol implementation must conform to the
specification defined by the Bluetooth SIG and, as is often the case
with protocol specifications, it is important to handle all the
(sometimes vast numbers of) possible cases and interactions that are
permitted by the specification. The net result is that a fairly complex
state machine is required to manage valid requests and responses from
remote devices, while also robustly handling domain errors (such as
invalid transactions from defective or even malicious devices), system
errors (such as failing to allocate enough memory), and faults (such as
typing errors in hard-coded constants).
In addition, there is the logic to map the API and
the protocol together. Although initially this may appear to be fairly
straightforward, for an open operating system this is rarely the case.
There can be multiple, distinct GAVDP clients using the protocol to
communicate with multiple devices, or even the same device. The stack is
required to co-ordinate these requests and responses in a robust and
efficient manner.
We hope to have convinced you that the Symbian OS
GAVDP/AVDTP protocol implementation is a complex component of software.
It is apparent that faults could occur locally in a number of places:
from incorrect usage of the API by clients, from lower layers corrupting
messages, and from mistakes in the complex logic used to manage the
protocol.
As with all software based on Symbian OS, it is
paramount that there are minimal faults in the released component. In
this case, the consequences of faults can be serious ranging from jitter
in the AV stream preventing end users from enjoying the content to
allowing DRM-protected data to be sent to an unauthorized device.
2. Solution
The basic principle of this solution is to 'panic' –
terminate the current thread of execution – as soon as an unexpected
condition (i.e. a fault) arises, rather than using an inappropriate
default or trying to ignore the event and carrying on regardless.
The reason for panicking is to prevent the thread
from attempting to do anything more and allowing the symptoms of the
fault to spread. In addition, it provides a convenient debugging point
at which a call stack, representing an execution snapshot, can be
retrieved. In debug mode, a panic can trigger a breakpoint and allow you
to enter your debugger.
This pattern explicitly encodes design constraints in
software and checks that they are being met. This prevents the scope of
a problem growing by restricting the issue to a single thread rather
than risking the entire device. This could be considered as forming the
foundation of a fault-tolerant system.
2.1. Structure
This pattern focuses on the concrete places within a software component where you can add lines of code, known as assertions or, more colloquially, as asserts,
where a check is performed that the design constraints for your
component are being met. It is when an assert fails that the current
thread is panicked.
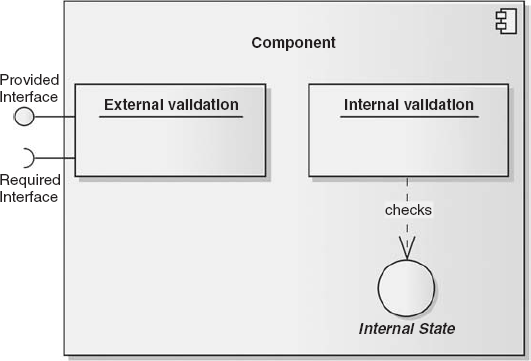
We classify asserts into two different types:
External asserts
check for the design constraints imposed on how software outside the
component interacts with it. An example would be clients of an API
provided by the component. If an external assert fails then it indicates
that the client has used the component incorrectly. You should be able
to test that these asserts fail during testing as they effectively form
part of the API itself.
Internal asserts
check for the design constraints imposed on the component itself. If an
internal assert fails then it indicates that there is a fault in the
component that needs to be fixed. The unit tests for the component
should seek to test that these asserts cannot be caused to fail.
Figure 1 illustrates how these two types of asserts are used to validate different aspects of the design.
Some concrete examples of where you might add asserts are:
within the implementation of a public interface
when a transition is made in a state machine so that only valid state changes are performed
checking
a class, or even a component, invariant within functions (an invariant
is a statement that can be made about the class or component that should
remain true irrespective of what operations you perform on it).
Of course, there are a number of situations in which
you would not wish to assert but which you would instead handle in a
more sophisticated manner. One such case is that of expected unexpected
errors. In plain English this is the set of errors that should have been
considered (by design), but whose arrival can occur unexpectedly at any
time. Often this type of error is either a system or a domain error. A
good example of this is the disconnection of a Bluetooth link, since it
can be disconnected at any time by a request from a remote device, noise
on 'the air', or by moving the devices out of radio range.
Another case that typically should not be externally
asserted is incorrect requests from a client that are sensitive to some
state of which the client is not aware. For instance, a client calling Read() on a communication socket before Connect() has been called is a state-sensitive request that can be asserted since the client should be aware of the socket's state.
However, you should not assert based on state from one client when
handling the request from another. This sounds obvious but is often much
less so in practice, especially if you have a state machine that can be
manipulated by multiple clients who know nothing of each other.
2.2. Dynamics
The sequence chart in Figure 2
illustrates how a class function could implement a rigorous scheme of
asserts. The function initially checks that the parameters passed in are
suitable in a pre-condition checking step as well as verifying that the
object is in an appropriate state to handle the function call. The
function then performs its main operation before executing a
post-condition assert that ensures a suitable output for the function
has been computed, before again checking that the object has not
violated any of its invariants.
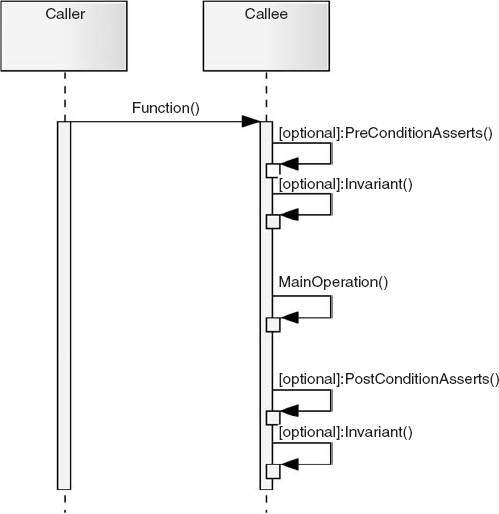
It's not essential that all functions conform to this
sequence; the diagram simply provides a general example of how a
function could implement this pattern.
By using this pattern to check the design contracts
internal to a component we have effectively produced a form of unit-test
code built into the component. However, these test steps are in a form
that needs to be driven as part of the standard testing for the
component. This pattern and testing are complementary since testing is
used to show that the implementation of a component's design is behaving
correctly (shown by the asserts) whilst the asserts aid the debugging
of any design violations (shown by the testing).
2.3. Implementation
Reducing the Impact of the Asserts
A naïve interpretation of this pattern would simply
be to always check as many conditions as are necessary to validate the
implementation of the design. Whilst for some types of software this may
be appropriate, it is often crucial to take into account the various
issues that this approach would introduce.
The two main ways that asserts impact your software
is through the additional code they add to an executable and the
additional execution time needed to evaluate them. A single assert might
only add a handful of bytes of code and take nanoseconds to evaluate.
However, across a component, or a system, there is potentially a
significant number of asserts, especially if every function implements
pre- and post-condition checking. For Symbian OS development, it is
often simply too expensive to use asserts liberally in production
software and so we need to be selective in where they are added.
One approach to this is to always enforce external
asserts because we have no control over client code and what they will
try to do. However, the same is normally not true for internal asserts
as these should never be triggered if
the software is operating correctly and hence a trade-off can be made
between the performance cost of asserts and the benefits they bring. The
simplest solution is to ensure that internal asserts are only present
in debug code. The assumption is that you are continually running your
test suite on both the debug and release versions of your component and
hence can have a reasonable level of confidence that the any new faults
introduced into the component will be identified during testing.
However, the consequences of this solution are that there will always be
some release-only faults that will be let through by this method and
will not be stopped by an assert.
A more sophisticated approach to dealing with the
internal asserts is to change which builds they are compiled into during
the development process. Initially you would choose to have them
compiled into both release and debug builds until you have confidence that enough faults have been removed from your component, at which point you could leave the asserts only in the debug builds.
Implementing a Single Assert
Symbian OS provides the following standard assert macros in e32def.h:
__ASSERT_ALWAYS(c,p)
Here c is a conditional expression which results in true or false and p is a statement which is executed if the conditional expression c is false.
__ASSERT_DEBUG(c,p)
The same as __ASSERT_ALWAYS(c,p) except that it is compiled out in release builds.
ASSERT(c)
The same as __ASSERT_DEBUG(c,p) except that it causes a USER 0 panic if c is false. Using this standard Symbian OS macro is no longer recommended since there's no way of identifying which ASSERT()
in a component caused a USER 0. Hence, it is common for components to
redefine the macro to provide more details that allow the asserts to be
distinguished during debugging.
__ASSERT_COMPILE(c)
This macro asserts that c
is true at compilation time and is particularly useful for checking
hard-coded constants although the error messages it causes the compiler
to output could be more informative.
In addition, you can use the following macros to help check class invariants in a consistent manner:
__DECLARE_TEST
This should be added as the last item in a class declaration so that a function called __DbgTestInvariant() is declared. It is your responsibility to implement the invariant checks and call User:: Invariant() to panic the thread if they fail.
__TEST_INVARIANT
This calls the __DbgTestInvariant() function in debug builds.
For more information on these macros, please see the Symbian Developer Library.
However, you still need to know how to cause a panic
if the assert fails. A panic is most commonly issued on the local
thread, by calling User :: Panic(const TDesC& aCategory, TInt aReason) which is declared in e32std.h. The category is a textual value,
and the reason is a numeric value; together they form a description of
the cause of a panic. This description is shown on the screen in a
dialog box as well as being sent to the debug output. For instance:
_LIT(KPanicCategory, "Fail Fast");
enum TPanicCode
{
EInvalidParameter,
EInvalidState,
EInappropriateCondition,
...
};
void CClass::Function(const TDesC& aParam)
{
__ASSERT_ALWAYS(aParam.Length() == KValidLength,
User::Panic(KPanicCategory, EInvalidParameter));
__ASSERT_DEBUG(iState == ESomeValidState,
User::Panic(KPanicCategory, EInvalidState));
// Function implementation
}
Using the parameters passed to Panic() in a
disciplined way provides useful debugging information. Notably, if the
category and reason uniquely map to the assert that caused the panic
then even if a stack trace or trace data for the fault is not available
then someone investigating the fault should still be able to identify
the condition that caused the problem. For external asserts, time spent
explicitly creating a unique panic category and reason combination for
every assert in the component is often time well spent. Taking the
example above, EInvalidParameter could become EInvalidParameterLengthForCClassFunction and EInvalidState may become EInvalidStateForCalling-CClassFunction, and so on.
One of the reasons for explicitly setting the
category and reason for external asserts is that they form part of the
API for clients of your component. Developers using the API will expect
consistency not only for its run-time behavior but also in how they
debug their client code, for which identifying a particular panic is
key. The use of external asserts helps to maintain compatibility for the
API of which they form a part. By documenting and enforcing the
requirements for requests made on an interface more rigidly (by failing
fast), it becomes easier to change implementations later as it is clear
that clients must have adhered to the specific criteria enforced by
asserts.
One problem with this is that the development cost of
explicitly assigning the category and reason for each separate panic is
proportional to the number of asserts and so can become time consuming.
An alternative that is well suited to internal asserts is to have the
panic category assigned automatically as the most significant part of
the filename and the reason as the line number:
#define DECL_ASSERT_FILE(s) _LIT(KPanicFileName,s)
#define ASSERT_PANIC(l) User::Panic(KPanicFileName().
Right(KMaxExitCategoryName),l)
#define ASSERT(x) { DECL_ASSERT_FILE(__FILE__);
__ASSERT_ALWAYS(x, ASSERT_PANIC(__LINE__) ); }
This does have one big disadvantage which is that you
need to have the exact version of the source code for the software
being executed to be able to work out which assert caused a panic since
the auto-generated reason is sensitive to code churn in the file. Not
only might the developer seeing the panic not have the source code, even
if he does the person attempting to fix the problem will probably have
difficulty tracking down which version of the file was being used at the
time the fault was discovered. However, for internal asserts that you
don't expect to be seen except during development of a component this
shouldn't be a problem.
Panicking the Correct Thread
It is critical to fail the appropriate entity when
using this pattern. For internal asserts, it is not necessarily an issue
since it is nearly always the local thread. However, for external
asserts policing requests from clients, it is not so straightforward:
In libraries, either statically or dynamically linked, it is the current thread.
In services residing in their own process, it is the remote thread that made the request.
For the latter case, when using Client–Server (see page 182), the client thread can be panicked using the RMessagePtr2::Panic() function:
void CExampleSession::ServiceL(const RMessage2& aMessage)
{
...
if(InappropriateCondition())
{
aMessage.Panic(KPanicCategory, EInappropriateCondition);
return;
}
...
}
Alternatively you can use RThread::Panic() to panic a single thread or RProcess::Panic() to panic a process and all of its threads.
Ultimately the choice of where and how to fail fast requires consideration of users of the software and some common sense.
2.4. Consequences
Positives
The software quality is improved since more
faults are found before the software is shipped. Those faults that do
still occur will have a reduced impact because they're stopped before
their symptoms, such as a hung application or corrupted data, increase.
The
cost of debugging and fixing issues is reduced because of the extra
information provided by panic categories and reasons, in addition to
problems being simpler because they're stopped before they cause
knock-on problems.
The maintainability of
your component is improved because the asserts document the design
constraints inherent in its construction.
Security is improved because faults are more likely to stop the thread executing than to allow arbitrary code execution.
Negatives
Security can be compromised by introducing
denial-of-service attacks since a carelessly placed assert can be
exploited to bring down a thread.
Carelessly placed external asserts can reduce the usability of an API.
Code
size is increased by any asserts left in a release build. On nonXIP
devices, this means increased RAM usage as well as additional disk space
needed for the code.
Execution performance is impaired by the additional checks required by the asserts left in a release build.
2.5. Example Resolved
The Symbian OS GAVDP/AVDTP implementation applies
this pattern in several forms. It is worth noting that the following
examples do not constitute the complete usage of the pattern; they are
merely a small set of concise examples.
API Guards
The GAVDP API uses the Fail Fast approach to ensure
that a client uses the API correctly. The most basic form of this is
where the API ensures that the RGavdp object has been opened before any further operations are attempted:
EXPORT_C void RGavdp::Connect(const TBTDevAddr& aRemoteAddr)
{
__ASSERT_ALWAYS(iGavdpImp, Panic(EGavdpNotOpen));
iGavdpImp->Connect(aRemoteAddr);
}
The implementation goes further to police the API usage by clients to ensure that particular functions are called at the appropriate time:
void CGavdp::Connect(const TBTDevAddr& aRemoteAddr)
{
__ASSERT_ALWAYS((iState == EIdle || iState == EListening),
Panic(EGavdpBadState));
__ASSERT_ALWAYS(iNumSEPsRegistered, Panic(
EGavdpSEPMustBeRegisteredBeforeConnect));
__ASSERT_ALWAYS(aRemoteAddr != TBTDevAddr(0),
Panic(EGavdpBadRemoteAddress));
__ASSERT_ALWAYS(!iRequesterHelper, Panic(EGavdpBadState));
...
}
Note that the above code has state-sensitive external
asserts which, as has been mentioned, should be carefully considered.
It is appropriate in this particular case because the RGavdp class must be used in conjunction with the MGavdpUser class,
whose callbacks ensure that the client has sufficient information about
whether a particular function call is appropriate or not.
Invariant, Pre- and Post-condition Checking
A lot of code written in Symbian OS uses asserts to
check design constraints and AVDTP is no exception. For performance
reasons, the majority of these asserts are only active in debug builds:
void CAvdtpProtocol::DoStartAvdtpListeningL()
{
LOG_FUNC
// Check that we haven't already got an iListener.
// NOTE: in production code we will leak an iListener.
// These are fairly small so not too severe.
__ASSERT_DEBUG(!iListener, Panic(EAvdtpStartedListeningAgain));
...
}
The example shows a good practice: using a comment to
explicitly state what will happen in release builds if the particular
fault occurs. In the code above, although we do not want to leak memory,
the debug assert combined with comprehensive testing should give us
confidence that this condition will never actually arrise.
The use of asserts is not limited to complex functions. Even simple functions can, and should, check for exceptional conditions:
void CManagedLogicalChannel::ProvideSAP(CServProviderBase* aSAP)
{
__ASSERT_DEBUG(aSAP, Panic(EAvdtpPassingNullSapOwnershipToChannel));
__ASSERT_DEBUG(!iLogicalChannelSAP, Panic(
EAvdtpPassingSapOwnershipToChannelThatAlreadyHasASap));
iLogicalChannelSAP = aSAP;
iLogicalChannelSAP->SetNotify(this);
}
The above example shows the use of a pre-condition check, firstly that the parameter to the function is not NULL, and secondly that the object upon which the function is called does not already have a Service Access Point (SAP) bound to it.
These last two example code snippets demonstrate the
use of panic reasons that are unique across the whole component by
design and probably across the whole of Symbian OS through the use of
the EAvdpt prefix. Although the names of the particular panic
reason enumeration values can be fairly long, they are self-documenting
and thus no accompanying comment is required. Furthermore, they provide a
good demonstration of how asserts can document the design constraints
of an implementation.
State Transition Checking
The checking of state transitions can be thought of
as a special case of invariant checking. The following function is the
base class implementation of the 'Set Configuration' event for an
abstract class representing an audio–video stream state as per the State
pattern [Gamma et al., 1994]:
void TAVStreamState::SetConfigurationL(
CAVStream& /*aStream*/,
RBuf8& /*aPacketBuffer*/,
CSignallingChannel& /*aSignallingChannel*/,
TBool /*aReportingConfigured*/,
TBool /*aRecoveryConfigured*/) const
{
LOG_FUNC DEBUGPANICINSTATE(EAvdtpUnexpectedSetConfigurationEvent);
User::Leave(KErrNotReady);
}
In this particular example, we can see the base class
implementation triggers an assert if in debug mode, but in a release
build the fault will be handled as an exceptional error. The reason for
this is that State classes, derived from TAVStreamState, which are by design expected to receive 'Set Configuration' events must explicitly override the SetConfigurationL()
function to provide an implementation to deal with the event. Failing
to provide a way to handle the implementation is considered to be a
fault.
3. Other Known Uses
This pattern is used widely throughout Symbian code and here we give just a select few:
Descriptors
Symbian
OS descriptors panic when an out-of-bound access is attempted. The
prevalent use of descriptors for buffers and strings in Symbian OS means
that the possibility of arbitrary code execution through a buffer
overflow attack against Symbian OS components is vastly reduced. This
type of panic is an external panic, as it forms part of the API to a
bounded region of memory.
Active Objects
The
active scheduler panics if it detects a stray signal rather than just
ignoring it as it indicates that there is an error with an asynchronous
request made via an active object. By panicking as soon as this
condition is detected, debugging the defect is much easier than trying
to track down why some notifications do not occur occasionally.
Symbian Remote Control Framework
This
component auto-generates the panic reason for its internal asserts
which are compiled only into debug builds. These asserts are liberally
used throughout the component.
4. Variants and Extensions
Passing Additional Debug Information when Panicking
The
usual procedure for assigning the category and reason for a panic is to
give the component name for the category and then just assign a fixed
number for the reason. However, the category can be up to 16 letters and
the reason is 32 bits so there are usually opportunities for additional
information to be given here. For instance the ALLOC panic is
used when a memory leak has been detected and the reason contains the
address of the memory. Also, some state machines that raise panics use
the bottom 16 bits of the reason to indicate which assert caused the
problem and the top 16 bits to indicate the state that it was in at the
time.
Invoking the Debugger when Failing an Assert
Symbian OS provides the __DEBUGGER()
macro which can be used to invoke a debugger as if you had manually
inserted a breakpoint where the macro is used. This does not result in
the thread being killed. The debugger is only invoked on the emulator
and if 'Just In Time' debugging has been enabled for the executing
process. In all other circumstances, nothing happens.
This variant combines the use of this macro with __ASSERT_DEBUG()
calls but otherwise applies the pattern described above. This allows
you to inspect the program state when the assert failed and so better
understand why it happened.