ADO.NET Data Services is yet another way for you to
access your SharePoint data at client side. Under this technology you
would use patterns and libraries that make data accessible over simple
HTTP -based technologies. This means that you can access the data over
simple HTTP -based URIs and use of standard HTTP verbs such as GET, PUT,
POST, and DELETE. Data is fetched in JSON or ATOM formats, so it is
portable across all platforms. Before I dive into real working examples
using ADO.NET Data Services and REST, let's examine some basics about
REST and ADO.NET Data services first.
1. ADO.NET Data Services and REST Basics
In order to begin playing with ADO.NET Data Services
in SharePoint 2010, let's begin by setting up some sample data in a
sample site. You can either create this data manually or use the
RawData.wsp solution package provided to create the data for you. Just
upload the RawData.wsp package to the Solution Gallery, activate, and
create a subsite based on the newly created site definition.
Start with a blank SharePoint site and create three lists, all of them based on the "Custom List" template.
Artists with just one column: Title
Albums: add a look up column pointing to Artists.Title
Songs: add two lookup columns, pointing to Artists.Title and Album.Title
What I just did is define my EDM (Entity Data Model).
Go ahead and fill the lists with some data. I have included RawData.wsp
as an export of my own site at this point with the associated code
download. If you wish, you can create a new site based on the blank site
definition, upload RawData.wsp as a user solution, and activate it to
get a site definition with the same data that I am working with.
With some data loaded, I can now start executing some
simple REST -based queries right through my web browser. So open
Internet Explorer and disable the feed reading view so you can view the
actual XML being sent back to you by the server. In Internet Explorer 8,
you can do this by going to Tools\Internet options\Content and click
Settings under the Feeds and Web Slices section. In the dialog box that
pops up, uncheck the check box next to Turn on feed reading view.
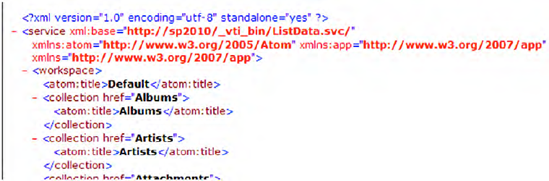
Great! Now visit http://sp2010/_vti_bin/ListData.svc. You should see some XML come back from the server, as shown in Figure 1.
In the scenario that it doesn't work telling you that the system could
not load "System.Data.Services.Providers.IDataServiceUpdateProvider",
please see http://blah.winsmarts.com/2010-4-WCF-ADONET_Data_Services_-_Could_not_load_type_'SystemDataServicesProvidersIDataServiceUpdateProvider'.aspx.
If you observe closely, this is nothing but an ATOM
feed. It is telling you all the lists that are available in this site.
Next visit this URL: http://sp2010/_vti_bin/ListData.svc/$metadata.
This URL sends you a little bit more XML back,
basically giving you the detailed structure of all the entities
available in the site. Think of this as WSDL for REST.
Now let's start querying individual lists. Visit this URL: http://sp2010/_vti_bin/ListData.svc/Artists.
This should send back, again as an ATOM feed, all the artists in the
Artists list. But what if I intended to filter based on a particular
artist? Could I pass the primary key for the artist and load only a
single entity instance?
Try visiting http://sp2010/_vti_bin/ListData.svc/$metadata one more time, and examine the metadata for the "ArtistsItem" EntityType closely. You should see a section as shown in Figure 2.

What this is telling you is that the ArtistsItem has a
key property, the equivalent of a primary key called ID. Thus it is
valid to pass in a URL such as http://sp2010/_vti_bin/ListData.svc/Artists(2) to fetch all the details for Artist with ID = 2. Go ahead, try it!
So now you can not only fetch a list of all artists,
but you can also filter on the primary key. Because the result is just
an ATOM feed it is very easy to consume it in very thin clients such as
JavaScript. Later on, I will also demonstrate getting results as JSON,
which is even easier for JavaScript to consume.
Now, could you do more interesting things, perhaps sort by a column? You can do so by visiting a URL such as http://sp2010/_vti_bin/ListData.svc/Artists?$orderby=Title.
Could you do paging? You can fetch the top few items by visiting a URL such as http://sp2010/_vti_bin/ListData.svc/Songs?$top=3. And then you can in effect do paging by skipping the first few rows by passing in a URL such as http://sp2010/_vti_bin/ListData.svc/Songs?$skip=3&top=3. You can also choose to add orderby and visit a URL such as http://sp2010/_vti_bin/ListData.svc/Songs?$skip=3&top=3&orderby=Title. In fact, you can continue to stack as many of these actions as you want. You can see how powerful this can get.
How about relationships between multiple entities?
You can do that, too. If I want to fetch a particular album and its
artist information in a single HTTP query, I could visit a URL such as http://sp2010/_vti_bin/ListData.svc/Albums(1)?$expand=Artist.
This allows me to go from child to parent. What if I want to go from
parent to child? I can use the $filter action to achieve that. For
instance, if I want to fetch all songs by Madonna, I could use a query
such as this:
http://sp2010/_vti_bin/ListData.svc/Songs?$filter=Artist/Title eq 'Madonna'.
Of course, I can use the $filter action to do simple filtering within a single list, such as this:
http://sp2010/_vti_bin/ListData.svc/Songs?$filter=Title eq 'Careless Whisper'.
So far, all the data you're getting back is an ATOM
feed. ATOM being xml can be extremely wordy. Frequently in Ajax base
scenarios, we have preferred to use JSON over ATOM. This is because JSON
is comparatively much more lightweight, and easily parsable in
JavaScript. Lucky for us, the REST -based APIs can easily return any of
the above results as either as ATOM or JSON, whichever you prefer. If
you wish to receive the results as JSON, instead of ATOM, all you need
to do is to modify the HTTP Header "Accept: application/json".
When you download and install Fiddler, it will
register itself as a proxy in Internet Explorer settings. It will then
be able to trace all the requests going between your browser to external
sites. Fiddler can also allow you to handcraft a request, and view both
the request and response all the way down to raw bytes.
However, the problem with using Fiddler with
SharePoint is that most SharePoint sites a protected behind some kind of
authentication. Fiddler cannot perform authentication for you, but it
does let you modify requests on the fly. Some simple modifications can
be done right through the UI, and some require a simple script or
writing a Fiddler extension.
In order to view the JSON equivalent of any
particular request, start Fiddler, start capturing traffic (File\Capture
Traffic), and go to the Filters tab and check the check box "Use
Filters". Also in the request headers section, choose to set the request
header Accept to application/json. This is shown in Figure 3.

Now back in Internet Explorer, visit http://sp2010/_vti_bin/ListData.svc/Songs?$skip=3&top=3 URL. You will probably see an error, as shown in Figure 4.
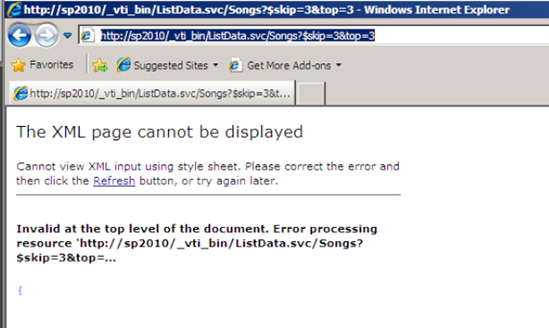
This is because Internet Explorer was expecting an
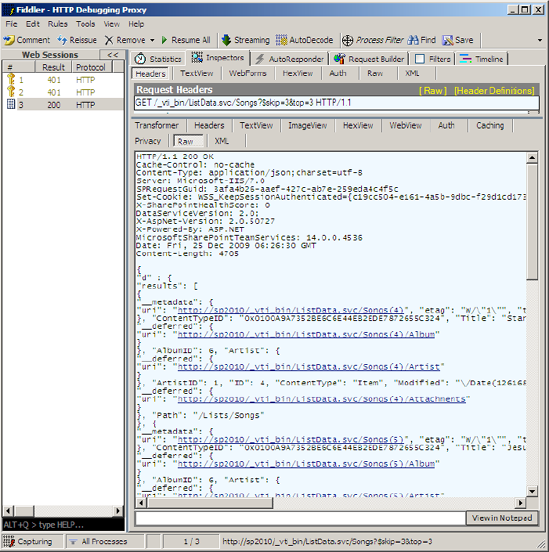
XML return, but instead the server sent JSON. However back in Fiddler,
double-click the HTTP 200 requests that were captured, and click the Raw
tab in the response. You should see the return JSON as shown in Figure 5.
All the examples that you've seen so far in this
section are the client telling the server that it wishes to query some
information. Querying is incredibly flexible. As you just saw, you have
the ability to query individual entities, lists of entities filtered by
criterion, parent-child relationships, and child to parent expansions.
Also the results are returned as either ATOM or JSON. I demonstrated the
usage of ATOM results right through the browser, and using Fiddler to
get the results formatted as JSON. You can do all this without having to
write a single line of code. Once we are over the basics, I will also
demonstrate writing real applications using the REST API.
So far, all the querying was done using a single HTTP
verb called GET. You can however also update, delete and add new
entities using the following HTTP verbs:
While all of these commands will work, it is probably
a lot easier to demonstrate to GET-based commands. This is because
GET-based commands can be easily executed from the browser. Because
Fiddler won't support NTLM or Kerberos or claims-based authentication,
to really view the behind-the-scenes usage of verbs other than GET, you
need to write a simple application using System.Net APIs. You can see an
example of calling and parsing JSON from C# code at http://blah.winsmarts.com/2009-12-How_to_parse_JSON_from_C-.aspx.
So far, all the examples demonstrated interacting
with ADO.NET Data Services, through the browser and maybe hacking them a
bit with Fiddler. In the real world, however, you will consume ADO.NET
data services in standard .NET applications, Silverlight applications,
and through JavaScript. Let's see an example of each one of these. In
each one of the examples, I will continue to use the same sample data I
had set up earlier.