The Open Data Protocol (OData) is a standard way of exposing relational data across a service
layer. OData is built on top of other standards including HTTP, JSON,
and Atom Publishing Protocol (AtomPub, which is
an XML format). OData represents a standard way to query and update
data that is web-friendly. It uses REST-based URI syntax for querying,
shaping, filtering, ordering, paging, and updating data across the
Internet.
1. How OData Works
OData is meant to make handling typical data
operations over HTTP simple. Although it is common in web services to
expose different methods for data operations such as Create, Read,
Update, and Delete (CRUD), OData takes a different approach. Instead of
creating different operations, it leans on the HTTP stack to allow for
different HTTP verbs to mean different operations. OData maps HTTP
verbs to these CRUD operations, as shown in Table 1.
TABLE 1 OData HTTP Verb Mappings
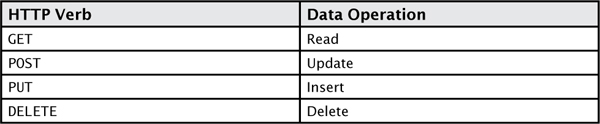
OData supports two data formats: JSON and
AtomPub. These formats are used to communicate in both directions. So
if you wanted to insert a record into an OData feed, you would use an
HTTP PUT to push a JSON or AtomPub version of a new entity. Each type of entity you can manipulate using OData is called an endpoint.
An endpoint is a type of entity that can be queried, inserted, updated,
and/or deleted (although not all operations might be permitted). When
you navigate to an OData feed, it returns a document that tells you
about the endpoints it exposes. For example, if you navigate to http://www.nerddinner.com/Services/OData.svc, it returns an AtomPub document, like so:
<?xml version="1.0" encoding="iso-8859-1" standalone="yes"?>
<service xml:base="http://www.nerddinner.com/Services/OData.svc/"
xmlns:atom="http://www.w3.org/2005/Atom"
xmlns:app="http://www.w3.org/2007/app"
xmlns="http://www.w3.org/2007/app">
<workspace>
<atom:title>Default</atom:title>
<collection href="Dinners">
<atom:title>Dinners</atom:title>
</collection>
<collection href="RSVPs">
<atom:title>RSVPs</atom:title>
</collection>
</workspace>
</service>
The collection elements in the AtomPub document tell us that the service supports two endpoints (Dinners and RSVPs). These endpoints have an href
attribute that points to their name. This link to the endpoint
indicates the path to the data. For example, to show the dinners in the
feed, you would resolve the Dinners href attribute to create a URI such as http://www.nerddinners.com/Services/OData.svc/Dinners.
By navigating to that URI, it returns an AtomPub document that contains all the dinners.
2. The URI
You might be wondering why OData returns an
AtomPub document. After all, if OData supports both AtomPub and JSON as
data formats, why is the browser returning AtomPub data? OData
determines the correct type of data to return based on HTTP Accept
headers. When an HTTP call is made, a header usually exists to say
which kinds of data the recipient can receive. Browsers make their
requests with HTML and XML as accepted types; OData detects this and
returns XML (AtomPub). If you were to call this in a context such as
from JavaScript on an HTML page, the Accept headers would have JSON as
an Accept header and OData would then return JSON instead.
The URI syntax says that the service URI can be post-pended with the path to a named endpoint. So both URIs are the path to the NerdDinner OData endpoints:
• http://www.nerddinner.com/Services/OData.svc/Dinners
• http://www.nerddinner.com/Services/OData.svc/RSVPs
When you look at the AtomPub data returned by the endpoints, each result is in an element called entry:
<entry>
<id>http://www.nerddinner.com/Services/OData.svc/Dinners(1)</id>
<title type="text" />
<updated>2011-02-13T00:02:47Z</updated>
<author>
<name />
</author>
<link rel="edit"
title="Dinner"
href="Dinners(1)" />
<link rel="..."
type="application/atom+xml;type=feed"
title="RSVPs"
href="Dinners(1)/RSVPs" />
<category term="NerdDinnerModel.Dinner"
scheme="..." />
<content type="application/xml">
<m:properties>
<d:DinnerID m:type="Edm.Int32">1</d:DinnerID>
<d:Title>ALT.NERD Dinner</d:Title>
<d:EventDate m:type="Edm.DateTime">
2009-02-27T20:00:00
</d:EventDate>
<d:Description>
Are you in town for the ALT.NET Conference? Are you a .NET person?
Join us at this free, fun, nerd dinner. Well, you pay for your food!
But, still! Come by Red Robin in Redmond Town Center at 8pm Friday.
</d:Description>
<d:HostedBy>shanselman</d:HostedBy>
<d:ContactPhone>503-766-2048</d:ContactPhone>
<d:Address>7597 170th Ave NE, Redmond, WA</d:Address>
<d:Country>USA</d:Country>
<d:Latitude m:type="Edm.Double">47.670172</d:Latitude>
<d:Longitude m:type="Edm.Double">-122.1143</d:Longitude>
<d:HostedById>shanselman</d:HostedById>
</m:properties>
</content>
</entry>
Although this format is usually hidden from you
on the phone, there are a couple of pieces of information in an entry
that are of interest. In the entry is a list of links. The first is an
“edit” link, which shows the address of the entry on its own. The
format takes the form of parentheses with the primary key of the entry. So to retrieve just this entry, you could use this link via the relative URI:
http://www.nerddinner.com/Services/OData.svc/Dinners(1)
The other link listed in this example is a
related entity link. To retrieve the list of RSVPs for this particular
dinner, you could also use the relative URI:
http://www.nerddinner.com/Services/OData.svc/Dinners(1)/RSVPs
This is at the heart of the relational nature
of the OData feed. You can navigate using simple REST-style URIs to get
at related entities.
As mentioned earlier, it depends on the HTTP
verb during the request as to what the endpoint does with the request.
In the browser, all the requests are GET requests, which
means they read the data. OData supports a number of query options that
enable you to decide how you want to retrieve the data. These query
options enable you to specify a query against the endpoint including
filtering, sorting, shaping, and paging. For instance, to sort the
dinners by date, you can use the $orderby query option:
http://www.nerddinner.com/Services/OData.svc/
Dinners?$orderby=EventDate
Table 2 shows the supported query options.
TABLE 2 OData Query Options
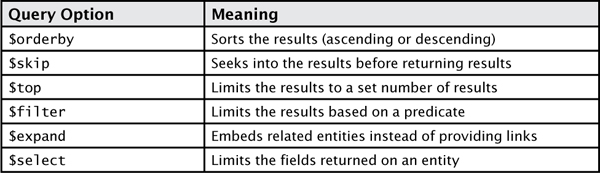
Each of these can be combined to change the result from the OData feed. Let’s look at each in the sections that follow.
$orderby
This query option enables you to specify one
or more field names (separated by a comma) to use when sorting the
results. Each field name can have the suffix “desc” added to mark that
the sorting should be done in descending order. Some examples include
the following:
http://.../Dinners?$orderby=Title
http://.../Dinners?$orderby=Title desc
http://.../Dinners?$orderby=Title,EventDate
http://.../Dinners?$orderby=Title desc,EventDate
http://.../Dinners?$orderby=Title desc,EventDate desc
$skip and $top
These query options are used to limit and span the number of results in the entire result. The $top query option specifies the maximum number of results to return and the $skip query option is used to specify how many of the results to not return before starting to return results. Although using the $top query option to return only a set number of results is typical on its own, $skip is used almost exclusively with the $top option to provide a paging mechanism. When using $top and $skip for paging, $skip should be preceded by the $top
query option so that the records are skipped first and then limited by
the number. Otherwise, you will not get the paging you expect. Here are
some samples:
http://.../Dinners?$top=10
http://.../Dinners?$skip=10&$top=10
$filter
The purpose of the $filter query
option is to provide a predicate with which to return only results that
match the predicate. The language definition for predicates is a robust
set of operators and functions. Typically, you will need to specify the
name of a field to use in the predicate along with an operator and/or
functions. The $filter query can specify the name of a simple field such as
http://.../Dinners?$filter=Country eq 'China'
In this example, Country is the field name followed by an operator (eq
means equals) and a value to compare it to. Strings should be delimited
by single quotes. Instead of the simple field name, you can use
navigation to a related entity as well (as long as it is a 1-to-1
relationship). For example:
http://.../Suppliers?$filter=Address/City eq 'Atlanta'
In this example, the Supplier has a property called Address that contains a City field. So you can filter the Suppliers by the city name in this way. Table 3 lists the operators, and Table 4 lists the functions you can use in a $filter query option.
TABLE 3 $filter Operators
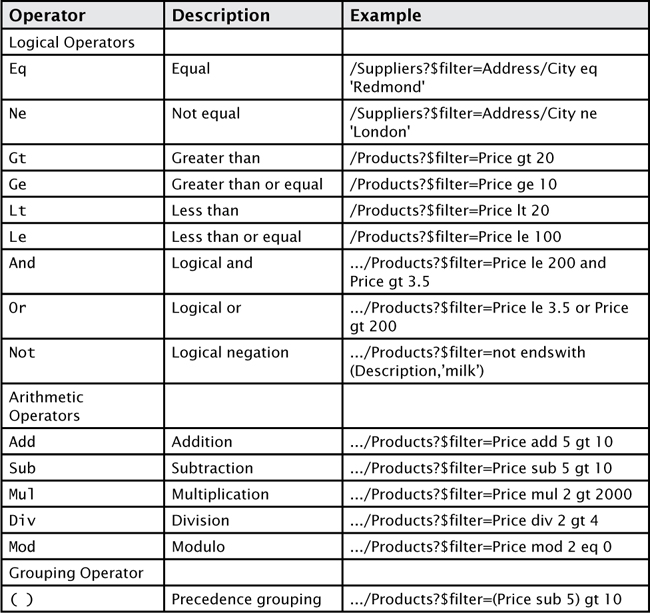
TABLE 4 $filter Functions

$expand
The purpose of this query option is to enable
you to embed specific related data in the results of a request. As you
saw earlier, you can access a related entity by following the path to
the related entries, like so:
http://.../Dinners(1)/RSVPs
The $expand query option lets you
return not only the main endpoint you are making a quest from, but also
the related entries in a single call. For instance, you can include the
RSVPs in the request for dinners, like so:
http://.../Dinners?$expand=RSVPs
This will return the dinners plus any RSVPs for
those dinners. If you have a complex chain of related entities such as
Customer→Order→OrderDetails→Products, a single $expand query option can include the entire chain by including the path to the deepest part of the object tree:
http://.../Customers?$expand=Orders/OrderDetails/Products
Finally, you can include multiple expansions by separating individual expansion query options with a comma:
http://.../Customers?$expand=Orders/OrderDetails,SalesPeople
This request would return the customers and
include the orders and the details for each order, as well as any
salespeople for each customer.
$select
This query option is used to limit the fields the endpoint returns in the request. The $select query option lets you specify a comma-delimited list of fields to return:
http://.../Dinners?$select=DinnerID,Title,EventDate
Use of this query option tells the OData feed to return only the specified fields:
<entry>
<id>http://www.nerddinner.com/Services/OData.svc/Dinners(1)</id>
<title type="text"></title>
<updated>2011-02-13T02:36:44Z</updated>
<author>
<name />
</author>
<link rel="edit" title="Dinner" href="Dinners(1)" />
<category term="NerdDinnerModel.Dinner" scheme="..." />
<content type="application/xml">
<m:properties>
<d:DinnerID m:type="Edm.Int32">1</d:DinnerID>
<d:Title>ALT.NERD Dinner</d:Title>
<d:EventDate m:type="Edm.DateTime">
2009-02-27T20:00:00
</d:EventDate>
</m:properties>
</content>
</entry>
Note that when you use the $select query option, you are specifying the fields to return for every entity. This affects when you use it in conjunction with the $expand query option in that you must include the fields you want from the related entities as well. For example, you could use $select to limit the fields from the main endpoint as well as the related entries:
/Dinners?$expand=RSVPs&$select=Title,EventDate,RSVPs/AttendeeName
This query would result in filtering the main endpoint (Dinners) but would include only the AttendeeName in the related entry (RSVPs).