A nonclustered
index contains a row for every row in the table, even rows with a large
number of duplicate key values where the nonclustered index will not be
an effective method for finding those rows. For these situations, SQL
Server 2008 introduces filtered indexes. Filtered indexes are an
optimized form of nonclustered indexes, created by specifying a search
predicate when defining the index. This search predicate acts as a
filter to create the index on only the data rows that match the search
predicate. This reduces the size of the index and essentially creates an
index that covers your queries, which return only a small percentage of
rows from a well-defined subset of data within your table.
Filtered indexes can provide the following advantages over full-table indexes:
Improved query performance and plan quality—
A well-designed filtered index improves query performance and execution
plan quality because it is smaller than a full-table nonclustered index
and has filtered statistics. Filtered statistics are more accurate than
full-table statistics because they cover only the rows contained in the
filtered index.
Reduced index maintenance costs—
Filtered indexes are maintained only when data modifications affect the
data values contained in the index. Also, because a filtered index
contains only the frequently accessed data, the smaller size of the
index reduces the cost of updating the statistics.
Reduced index storage costs—
Filtered indexes can reduce disk storage for nonclustered indexes when a
full-table index is not necessary. You can replace a full-table
nonclustered index with multiple filtered indexes without significantly
increasing the storage requirements.
Following are some of the situations in which filtered indexes can be useful:
When a column contains mostly NULL values, but your queries search only for rows where data values are NOT NULL.
When
a column contains a large number of duplicate values, but your queries
typically ignore those values and search only for the more unique
values.
When you want to enforce uniqueness on a subset of values—for example, a column on which you want to allow NULL values. A unique constraint allows only one NULL value; however, a filtered index can be defined as unique over only the rows that are NOT NULL.
When
queries retrieve only a particular range of data values and you want to
index these values but not the entire table. For example, you have a
table that contains a large number of historical values, but you want to
search only values for the current year or quarter. You can create a
filtered index on the desired range of values and possibly even use the INCLUDE option to add columns so your index fully covers your queries.
Now, you may be asking, “Can’t some of the preceding
solutions be accomplished using indexed views?” Yes, they can, but
filtered indexes provided a better alternative. The most significant
advantage is that filtered indexes can be used in any edition of SQL
Server 2008, whereas indexed views are chosen by the optimizer only in
the Developer, Enterprise, and Datacenter Editions unless you use the NOEXPAND
hint in other editions. In addition, filtered indexes have reduced
index maintenance costs (the query processor uses fewer CPU resources to
update a filtered index than an indexed view); the Query Optimizer
considers using a filtered index in more situations than the equivalent
indexed view; you can perform online rebuilds of filtered indexes
(online index rebuilds are not supported for indexed views); and
filtered indexes can be nonunique, whereas indexed views must be unique.
Based on these advantages, it is recommended that you
use filtered indexes instead of indexed views when possible. Consider
replacing indexed views with filtered indexes when the view references
only one table, the view query doesn’t return computed columns, and the
view predicate uses simple comparison logic and doesn’t contain a view.
Creating and Using Filtered Indexes
To define filtered indexes, you use the normal CREATE INDEX command but include a WHERE
condition as a search predicate to specify which data rows the filtered
index should include. In the current implementation, you can specify
only simple search predicates such as IN; the comparison operators IS NULL, IS NOT NULL, =, <>, !=, >, >=, !>, <, <=, !<; and the logical operator AND. In addition, filtered indexes cannot be created on computed columns, user-defined data types, Hierarchyid, or spatial types.
For example, assume you need to search only the sales table in the bigpubs2008 database for sales since 9/1/2008. The majority of the rows in the sales table have order dates prior to 9/1/2008. To create a filtered index on the ord_date column, you would execute a command like the following:
create index ord_date_filt on sales (ord_date)
WHERE ord_date >= '2008-09-01 00:00:00.000'
Now, let’s look at a couple queries that may or may
not use the new filtered index. First, let’s consider the following
query looking for any sales for 9/15/2008:
select * from sales
where ord_date = '9/15/2008'
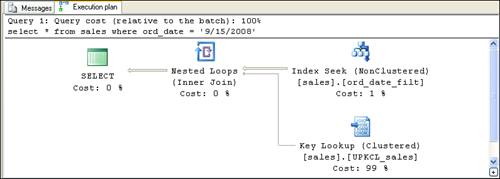
If you look at the execution plan in Figure 1, you can see that the filtered index, ord_date_filt, is used to locate the qualifying row values. The clustered index, UPKCL_sales, is used as the row locator to retrieve the data rows .
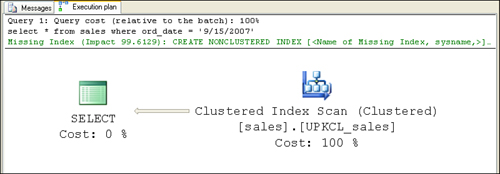
If you run the following query using a data values
that’s outside the range of values stored in the filtered index, you see
that the filtered index is not used (see Figure 2):
select * from sales
where ord_date = '9/15/2008'
Now let’s consider a query that you might expect would use the filtered index but does not:
select stor_id, qty from sales
where ord_date > '9/15/2008'
Now, you might expect that this query would use the
filtered index because the data values are within the range of values
for the filtered index, but due to the number of rows that match, SQL
Server determines that the I/O cost of using the filtered nonclustered
index to locate the matching rows and then retrieve the data rows using
the clustered index row locators requires more I/Os than simply
performing a clustered index scan of the entire table (the same query
plan as shown in Figure 2).
In this case, you might want to use included columns
on the filtered index so that the data values for the query can be
retrieved using index covering without incurring the extra cost of using
the row locators to retrieve the actual data rows. The following
example creates a filtered index on ord_date that includes stor_id and qty:
create index ord_date_filt2 on sales (ord_date)
INCLUDE (qty, stor_id)
WHERE ord_date >= '2008-09-01 00:00:00.000'
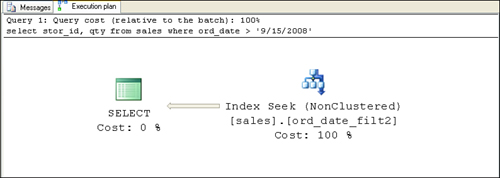
If you rerun the same query and examine the query
plan, you see that the filtered index is used this time, and SQL Server
uses index covering (see Figure 3). You can tell that it’s using index covering with the ord_dat_filt2
index because there is no use of the clustered index to retrieve the
data rows. Using the row locators is unnecessary because all the
information requested by the query can be retrieved from the index leaf
rows that contain the values of the included columns as well.
Creating and Using Filtered Statistics
Similar to the way you use filtered indexes, SQL
Server 2008 also lets you create filtered statistics. Like filtered
indexes, filtered statistics are also created over a subset of rows in
the table based on a specified filter predicate. Creating a filtered
index on a column autocreates the corresponding filtered statistics. In
addition, filtered statistics can be created explicitly by including the
WHERE clause with the CREATE STATISTICS statement.
Filtered
statistics can be used to avoid a common issue with statistics where
the cardinality estimation is skewed due to a large number of NULL or duplicate values, or due to a data correlation between columns. For example, let’s consider the titles table in the bigpubs2008 database. All the cooking books (type = 'trad_cook' or 'mod_cook') are published by a single publisher (pub_id = '0877').
However, SQL Server stores column-level statistics on each of these
columns independent of each other. Based on the statistics, SQL Server
estimates there are six rows in the titles table where pub_id = '0877', and five rows where the type is either 'trad_cook' or 'mod_cook'.
However, let’s assume you were to execute the following query:
select * from titles where pub_id = '0877'
and type in ('trad_cook', 'mod_cook')
When the Query Optimizer estimates the selectivity of this query where each search predicate is part of an AND
condition, it assumes the conditions are independent of one another and
estimates the number of matching rows by taking the intersection of the
two conditions. Essentially, it multiplies the selectivity of each of
the two conditions together to determine the total selectivity. The
selectivity of each is 0.011 (6/537) and 0.009 (5/537), which, when
multiplied together, comes out to approximately 0.0001, so the optimizer
estimates at most only a single row will match. However, because all
five cooking books are published by pub_id '0877', in actuality a total of five rows match.
Now, in this example, the difference between one row
and five rows is likely not significant enough to make a big difference
in query performance, but a similar estimation error could be quite
large with other data sets, leading the optimizer to possibly choose an
inappropriate, and considerably more expensive, query plan.
Filtered statistics can help solve this problem by
letting you capture these types of data correlations in your column
statistics. For example, to capture the fact that all cooking books are
also published by the same publisher, you could create the filtered
statistics using the following statement:
create statistics pub_id_type on titles (pub_id, type)
where pub_id = '0877' and type in ('trad_cook', 'mod_cook')
When these filtered statistics are defined and the
same query is run, SQL Server uses the filtered statistics to determine
that the query will match five rows instead of only one.
Although using this solution could require having to
define a number of filtered statistics, it can be effective to help fix
your most critical queries where cardinality estimates due to data
correlation or data skew issues are causing the Query Optimizer to
choose poorly performing query plans.