Service-level agreement, recovery point objective, recovery time objective, high availability, and disaster recovery
are common terms used when discussing availability. In this section, we
will discuss each of these terms with regard to a messaging system,
which is part of a larger IT ecosystem.
Service-Level Agreements
A service-level agreement (SLA) is an
agreement between a business and an IT vendor, which defines the
services that the IT vendor will deliver to the business, as well as
the uptime, or availability, of each service. The SLA must include how
availability will be measured. This could be a complex exercise,
depending on the constituent pieces of each service. As an example, for
which of the following is the Exchange storage tier considered
available?
- The information service is started and/or the database is mounted.
- Monitoring software can retrieve an item from a nominated mailbox.
- Only 10 percent of the end users are suffering from a degraded Outlook experience when opening a mail item.
How SLAs are measured and reported is an
important matter when documenting requirements. It is one of the items
that you must clarify, turning assumptions into documented facts.
RPO and RTO
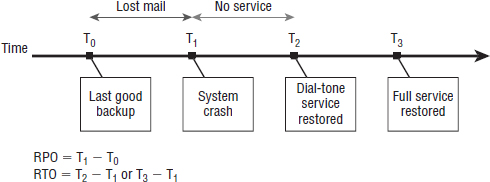
Recovery point objective (RPO) and recovery time objective (RTO) factor strongly in SLA definitions. Figure 1
represents an example of a very simple system or non-highly-available
server. It is worth starting with a simple example in order to baseline
your understanding of these concepts. Just be aware that the example
shown in Figure 4.2 is not representative of all the possible highly available configurations that are achievable using Exchange 2013.
Recovery Point Objective The recovery point objective (RPO)
is the allowable period for which data can be lost due to an incident.
For example, a backup is normally completed at 4 a.m. and the next
backup is scheduled for 24 hours later. The RPO is considered to be 24
hours. If a 24-hour RPO is unacceptable, then another backup method is
required that is able to deliver a lower RPO.
Recovery Time Objective The recovery time objective (RTO) is the allowable period in which the service is restored without data (T2 - T1) or the service is restored with data (T3 - T1).
FIGURE 1 Interdependent systems Time Credit: Boris Lokhvitsky
Defining High Availability and Disaster Recovery
High availability (HA) and disaster recovery (DR)
are sometimes incorrectly used interchangeably when, in fact, they are
quite different from each other. The one thing that they do have in
common is that because of some level of duplication of hardware,
software, networks, storage, or other components, the overall cost of
the system goes up, commensurate with the level of redundancy required.
HIGH AVAILABILITY
A high availability (HA) system is defined
as a system that includes redundant components that increase the
availability or fault tolerance of the overall system in a
near-transparent manner and confined within a defined geography. It is
also important to note that HA is a technology-driven function; that
is, the technology used in making the system highly available is often
the same one that initiates a failover to another available system or
component of that system. In other words, IT is responsible as the
initiator of the failover as well as being the decision maker to fail a
system over.
DISASTER RECOVERY
Disaster recovery (DR) is defined as the
restoration of an IT-based service. It includes the use of a separate
site or geography, and it addresses the failure of an entire system or
datacenter containing that system. It includes the use of people and
processes to make DR possible. Lastly, DR is hardly ever seamless or
swift.
FAILOVER VS. SWITCHOVER
Failover is a term that denotes the
automatic nature of highly available systems moving from one state to
another, or switching over components, in order to remain available.
Switchover, in contrast, is the equivalent
of having to pull a big, old-fashioned high-current switch, which
initiates the set of processes that move the service(s) from one
datacenter location to another.
Consider this example:
Datacenter A houses multiple copies of data within a highly resilient
cluster representing the implementation of an email service. Datacenter
B has a single server with a near-identical specification as one of the
servers in Datacenter A, except that it has a tape drive attached. If
Datacenter A is lost, a restore of the last-known good backup will
occur in Datacenter B—however long it takes. From that point forward,
the single server in Datacenter B represents the restoration of the
service that used to live in Datacenter A. There may be a significant
gap in the data restored in Datacenter B, depending on when the outage
occurred, as well as the point in time of the last known good backup.
If no good backup can be found, then Datacenter B will offer a “dial
tone” service for email, which means that customers may send and
receive email. However, no historical mail, contacts, or calendar
information will be present in their mailboxes. There is a sharp
contrast between what was implemented in Datacenter A versus what was
implemented in Datacenter B.
This kind of dramatic contrast
between locations can be expected as companies figure out how to
balance the cost of a DR facility with the stated RPO and RTO. The
lower the RPO and RTO, the higher the cost of the overall solution.