Now that you have a better understanding of the
storage structures in SQL Server, it’s time to look at how SQL Server
maintains and manages those structures when data modifications are
taking place in the database.
1. Inserting Data
When you add a data row to a heap table, SQL Server
adds the row to the heap wherever space is available. SQL Server uses
the IAM and PFS pages to identify whether any pages with free space are
available in the extents already allocated to the table. If no free
pages are found, SQL Server uses the information from the GAM and SGAM
pages to locate a free extent and allocate it to the table.
For clustered tables, the new data row is inserted to
the appropriate location on the appropriate data page relative to the
clustered index key order. If no more room is available on the
destination page, SQL Server needs to link a new page in the page chain
to make room available and add the row. This is called a page split.
In addition to modifying the affected data pages when
adding rows, SQL Server needs to update all nonclustered indexes to add
a pointer to the new record. If a page split occurs, this incurs even
more overhead because the clustered index needs to be updated to store
the pointer for the new page added to the table. Fortunately, because
the clustered key is used as the row locator in nonclustered indexes
when a table is clustered, even though the page and row IDs have
changed, the nonclustered index row locators for rows moved by a page
split do not have to be updated as long as the clustered key column
values remain the same.
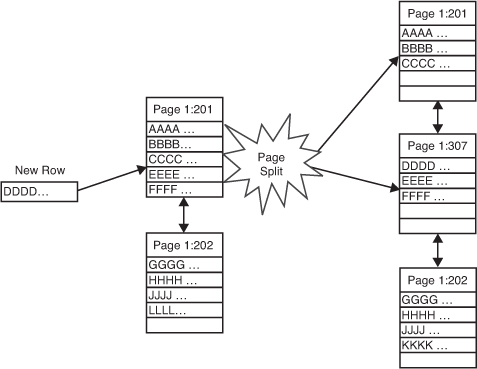
Page Splits
When a page split occurs, SQL Server looks for an
available page to link into the page chain. It first tries to find an
available page in the same extent as the pages it will be linked to. If
no free pages exist in the same extent, it looks at the IAM to determine
whether there are any free pages in any other extents already allocated
to the table or index. If no free pages are found, a new extent is
allocated to the table.
When a new page is found or allocated to the table
and linked into the page chain, the original page is “split.”
Approximately half the rows are moved to the new page, and the rest
remain on the original page (see Figure 1).
Whether the new page goes before or after the original page when the
split is made depends on the amount of data to be moved. In an effort to
minimize logging, SQL Server moves the smaller rows to the new page. If
the smaller rows are at the beginning of the page, SQL Server places
the new page before the original page and moves the smaller rows to it.
If the larger rows are at the beginning of the page, SQL Server keeps
them on the original page and moves the smaller rows to the new page
after the original page.
After determining where the new row goes between the
existing rows and whether the new page is to be added before or after
the original page, SQL Server has to move rows to the new page. The
simplified algorithm for determining the split point is as follows:
1. | Place first row (with the lowest clustered key value) at the beginning of first page.
|
2. | Place the last row (with the highest clustered key value) on the second page.
|
3. | Place the row with the next lowest clustered key value on the first page after the existing row(s).
|
4. | Place the next-to-last row (with the second highest clustered key value) on the second page.
|
5. | Continue alternating back and forth until the space between the two pages is balanced or one of the pages is full.
|
In some situations a double split can occur. If the
new row has to go between two existing rows on a page, but the new row
is too large to fit on either page with any of the existing rows, a new
page is added after the original. The new row is added to the new page, a
second new page is added after that, and the remaining original rows
are inserted into the second new page. An example of a double split is
shown in Figure 2.

Note
Although page splits are expensive when they occur,
they do generate free space in the split pages for future inserts into
those pages. Page splits also help keep the index tree balanced as rows
are added to the table. However, if you monitor the system with
Performance Monitor and are seeing hundreds of page splits per second,
you might want to consider rebuilding the clustered index on the table
and applying a lower fill factor to provide more free space in the
existing pages. This can help improve system performance until
eventually the pages fill up and start splitting again. For this reason,
some shops supporting high-volume online transaction processing (OLTP)
environments with a lot of insert activity rebuild the indexes with a
lower fill factor on a daily basis.
2. Deleting Rows
What
happens when rows are deleted from a table? How, and when, does SQL
Server reclaim the space when data is removed from a table?
Deleting Rows from a Heap
In a heap table, SQL Server does not automatically
compress the space on a page when a row is removed; that is, the rows
are not all moved up to the beginning of the page to keep all free space
at the end, as SQL Server did in versions prior to 7.0. To optimize
performance, SQL Server holds off on compacting the rows until the page
needs contiguous space for storing a new row.
Deleting Rows from an Index
Because the data pages of a clustered table are
actually the leaf pages of the clustered index, the behavior of data row
deletes on a clustered table is the same as row deletions from an index
page.
When rows are deleted from the leaf level of an
index, they are not actually deleted but are marked as ghost records.
Keeping the row as a ghost record makes it easier for SQL Server to
perform key-range locking . If ghost records were not used, SQL Server
would have to lock the entire range surrounding the deleted record. With
the ghost record still present and visible internally to SQL Server (it
is not visible in query result sets), SQL Server can use the ghost
record as an endpoint for the key-range lock to prevent “phantom”
records with the same key value from being inserted, while allowing
inserts of other values to proceed.
Ghost records do not stay around forever, though. SQL
Server has a special internal housekeeping process that periodically
examines the leaf level of B-trees for ghost records and removes them.
This is the same thread that performs the autoshrink process for
databases.
Whenever you delete a row, all nonclustered indexes
need to be updated to remove the pointers to the deleted row. Nonleaf
index rows are not ghosted when deleted. As with heap tables, however,
the space is not compressed on the nonleaf index page until space is
needed for a new row.
Reclaiming Space
Only when the last row is deleted from a data page is
the page deallocated from the table. The only exception is if it is the
last page remaining; all tables must have at least one page allocated,
even if it’s empty. When a deletion of an index row leaves only one row
remaining on the page, the remaining row is moved to a neighboring page,
and the now-empty index page is deallocated.
If the page to be deallocated is the last remaining
used page in a uniform extent allocated to the table, the extent is
deallocated from the table as well.
3. Updating Rows
SQL
Server 2008 performs row updates by evaluating the number of rows
affected, whether the rows are being accessed via a scan or index
retrieval and whether any index keys are being modified, and
automatically chooses the appropriate and most efficient update strategy
for the rows affected. SQL Server can perform two types of update
strategies:
In-place updates
Not-in-place updates
In-Place Updates
In SQL Server 2008, in-place updates are performed as often as possible to minimize the overhead of an update. An in-place update means that the row is modified where it is on the page, and only the affected bytes are changed.
When an in-place update is performed, in addition to
the reduced overhead in the table itself, only a single modify record is
written to the log. However, if the table has a trigger on it or is
marked for replication, the update is still done in place but is
recorded in the log as a delete followed by an insert (this provides the
before-and-after image for the trigger that is referenced in the inserted and deleted tables).
In-place updates are performed whenever a heap is
being updated and the row still fits on the same page, or when a
clustered table is updated and the clustered key itself is not changed.
You can get an in-place update if the clustered key changes but the row
does not have to move; that is, the sorting of the rows wouldn’t change.
Not-In-Place Updates
If the change to a clustered key prevents an in-place
update from being performed, or if the modification to a row increases
its size such that it can no longer fit on its current page, the update
is performed as a delete followed by an insert; this is referred to as a
not-in-place update.
When performing an update that affects multiple index
keys, SQL Server keeps a list of the rows that need to be updated in
memory, if it’s small enough; otherwise, it is stored in tempdb. SQL Server then sorts the list by index key and type of operation (delete or insert). This list of operations, called the input stream,
consists of both the old and new values for every column in the
affected rows as well as the unique row identifier for each row.
SQL Server then examines the input stream to
determine whether any of the updates conflict or would generate
duplicate key values while processing (if they were to generate a
duplicate key after processing, the update cannot proceed). It then
rearranges the operations in the input stream in a manner to prevent any
intermediate violations of the unique key.
For example, consider the following update to a table with a unique key on a sequential primary key:
update table1 set pkey = pkey + 1
Even
though all values would still be unique when the update finished, if
the update were performed internally one row at a time in sequential
order, it would generate duplicates during the intermediate processing
as the pkey value was incremented and matched the next pkey
value. SQL Server would rearrange and rework the updates in the input
stream to process them in a manner that would avoid the duplicates and
then process them a row at a time. If possible, deletes and inserts on
the same key value in the input stream are collapsed into a single
update. In some cases, you might still get some rows that can be updated
in place.
Forward Pointers
As mentioned earlier, when page splits on a clustered
table occur, the nonclustered indexes do not need to be updated to
reflect the new location of the rows because the row locator for the row
is the clustered index key rather than the page and row ID. When an
update operation on a heap table causes rows to move, the row locators
in the nonclustered index would need to be updated to reflect the new
location or the rows. This could be expensive if there were a larger
number of nonclustered indexes on the heap.
SQL Server 2008 addresses this performance issue
through the use of forward pointers. When a row in a heap moves, it
leaves a forward pointer in the original location of the row. The
forward pointer avoids having to update the nonclustered index row
locator. When SQL Server is searching for the row via the nonclustered
index, the index pointer directs it to the original location, where the
forward pointer redirects it to the new row location.
A row never has more than one forward pointer. If the
row moves again from its forwarded location, the forward pointer stored
at the original row location is updated to the row’s new location.
There is never a forward pointer that points to another forward pointer.
If the row ever shrinks enough to fit back into its original location,
the forward pointer is removed, and the row is put back where it
originated.
When a forward pointer is created, it remains unless
the row moves back to its original location. The only other circumstance
that results in forward pointers being deleted occurs when the entire
database is shrunk. When a database file is shrunk and the data
reorganized, all row locators are reassigned because the rows are moved
to new pages.