Reporting covers a myriad of
things, such as notifying customers, the business of system
availability metrics, or system usage capacity reports showing
availability headroom and trending.
Types of System Availability
It sometimes surprises design teams that there
are two types of system availability: one that is presented to the
business and one that is used within IT.
Business availability is generally
a straightforward statement of system availability. That is, it is a
statement of the availability of the system over a specific duration.
Downtime during system maintenance windows and so forth is considered
to be unavailable time. Sometimes, this value is actually calculated
manually based on incident records and is not generated by system
availability monitoring software.
IT availability data is usually
more detailed, and it will take scheduled system maintenance windows
into account. Typically, this data will be generated via a system
monitoring application, and it will indicate periods of service outage
and downtime during maintenance as available—even though, strictly
speaking, the system was down.
Most system monitoring tools offer the
ability to generate IT availability data, and the reports and charts
that are produced are tailored to the IT audience; that is, they
consist of relatively technical, jargon-rich information. On the other
hand, business availability reports tend to be jargon free and simply
state the system availability number for the month.
Trending
Trending is the taking of historical
observations and using that data to predict the future. As anyone who
has tried to predict the future knows, it's not often easy or accurate.
Some things, however, are easier to predict than others, while,
generally speaking, the farther into the future we wish to predict, the
more imprecise things become.
Thirty years ago, weather forecasts were
mostly inaccurate. In 2012, the Met Office (the United Kingdom's
national weather service) ranked their five-day predictions to be as
accurate as their 24-hour predictions were 30 years ago. This increase
in prediction accuracy is mostly attributed to having precise
historical data and more extensive observations from around the globe
to work with.
The same logic applies when you are trying
to make predictions about your Exchange infrastructure—the more
information you have available, the more accurately you can predict
what will happen next. Storage capacity usage is a common example.
Imagine that you had capacity data for 100 mailboxes over the last six
weeks compared to data for 10,000 mailboxes over the last six years.
The smaller sample size will yield a less accurate picture of growth
within the organization, especially if it was taken during a holiday
period or during a particularly busy time. Moreover, a few of the 100
mailboxes may be especially heavy users, skewing the average. Having a
significant historical data size available plus a representative sample
size on which to base prediction trends is vital. There are various
statistical methods for determining minimum sample
sizes for a population. For Exchange trending, however, we recommend
taking the simplest approach possible and recording trending data for
as many users as you possibly can.
The next step is to know what kind of
information is available that you should trend. As a general rule, the
following are areas that benefit most from some form of trending:
- Storage capacity
- Network utilization
- System resources
- Service usage
- Failure events
Storage capacity trending is
obviously not unique to Exchange. However, Exchange does bring with it
some interesting nuances. Exchange storage capacity trending is made up
of various sub-categories, including the following:
- Mailbox databases
- Transaction logs
- Content index
- Transport queues
- Tracking and protocol logs
MAILBOX DATABASES TRENDING
It is important to understand that Exchange
databases are not just made up of mailbox data; that is, there is other
“stuff” in the database including database indexes (a structure to
speed up data access), white space (empty pages that can be used to
write data), and items that have been deleted that nonetheless are
retained. Also, Exchange will never regain used storage space—even if
the data inside the database shrinks. For instance, if you moved half
of the mailboxes from one database to another, the source mailbox
database would remain the same size, even once all of the deleted items
have been purged. This is important since it means that there are many
factors that can influence the size of mailbox databases. For example,
some mailboxes may be moved from database to database leaving behind
white space. This white space exists within the database, and it is not
reclaimed from the disk. Thus, the actual storage capacity used on the
disk remains the same. However, when new data is written to the
database, Exchange will try to make use of the white space before
extending the size on disk. This behavior can lead to unusual storage
capacity data reports on Exchange Servers, and it is another reason why
it's useful to have as much historical data available as possible.
Short-term capacity trending for Exchange databases is usually
meaningless. Try to get at least 12 months' worth of “steady state”
capacity data before trying to predict storage capacity trends for
Exchange.
TRANSACTION LOG TRENDING
Transaction log capacity trending may not
initially seem like an interesting metric for trending. However, this
metric provides two interesting pieces of information. First, the log
generation rate is a very good way to observe the rate of change within
the database, and second, if we know how many
logs are generated per hour, it tells us how long we can potentially go
without a sustained database copy outage (or backup if native data
protection is not being used). Customers who have deployed a multicopy
native data protection DAG often miss the second point; that is, they
are relying on Exchange database copies and also potentially lagged
copies rather than taking backups. They will then configure Continuous Replication Circular Logging (CRCL)
to truncate the transaction log files automatically once they have been
successfully copied, inspected on lagged copies, and replayed on all
other nonlagged database copies. The key here is that the transaction
log files do not get truncated unless they have been copied, inspected,
and replayed on all other database copies. If you have a situation
where you have four database copies and one is in a failed state, then
the transaction log drives on all of the other database copies
will begin to fill up. If this is left unchecked, the database will
dismount. Therefore, having good trending data for your transaction log
generation rate will govern how long the support teams have to resolve
database problems before they affect service. Quite often, this value
will have been predicted during the design phase but never checked or
validated in production. Furthermore, the rate of transaction log file
generation can change from service pack to service pack. This situation
affected many customers when they deployed Exchange Server 2007 SP1,
which radically increased the number of transaction logs generated.
TIP The easiest way to gather transaction
log file generation data is from a lagged copy, since these are
persisted for 24 hours or more.
CONTENT INDEX TRENDING
The content index (CI) has changed
significantly in Exchange 2013. The content index provides the ability
to search mailbox data more quickly and effectively by creating a
keyword index for each item stored within the Exchange database. In
previous versions, there was a rough rule of thumb that said to account
for 10 percent of the mailbox database for CI data. This guidance has
changed for Exchange Server 2013 and CI database is now roughly 20% as
large as the Mailbox Database. From our lab environment observations,
the new CI database in Exchange 2013 appears to be roughly 7 percent as
large as the mailbox database that it is indexing. It is not generally
required to record or trend the CI space usage explicitly, but be aware
that it exists in the same folder as the mailbox database and it
requires additional space.
MESSAGE QUEUE TRENDING
Although there is no longer a specific transport
role for Exchange Server 2013, the old Transport role has simply been
incorporated into the Mailbox role. Message delivery is now a
combination of the Front End Transport service on the Client Access
role and the Transport service on the Mailbox role. This means that
there is still a mail.que database on every Exchange 2013 Mailbox server but no mail.que
on the Client Access Server unless it is collocated with the Mailbox
role. The transport queue holds email messages that are queued for
delivery or that Exchange is retaining as part of the new Safety Net
feature. Because of this feature, most organizations will store the mail.que
on a dedicated LUN. Trending storage capacity for the message queue
database is nontrivial since, like the mailbox database file, it does
not shrink as data is removed. From a trending perspective, it is
sufficient to monitor the storage capacity required for this database
file. It is rare, however, to see problems caused by a lack of space
for the transport database because of the large size of today's hard
drives and the relatively small size of the database.
WARNING Watch out
for the transport queue database growing in the event of a failure that
impacts message delivery. This will cause the database to
grow—potentially very quickly—and even once the fault has been
resolved, the database file will not shrink. Our advice in this
scenario is to ensure that you have a process in place to shrink the mail.que file after an event that causes an exceptionally large number of messages to be queued.
Because of Safety Net data being stored
within the database, the recommended way to remove white space is to
perform an offline defragmentation via the eseutil /d
command. This will require taking the transport server offline for the
duration of the process. If you have multiple Exchange Servers within
the AD site, however, it is possible to take one offline and defragment
the databases one at a time until they are all back to a normal size
without affecting message delivery.
TRACKING/PROTOCOL LOG TRENDING
Message tracking logs are text files that
contain routing and delivery information for every message that was
handled by the Exchange Server. These files are used to track messages
throughout the organization. The longer the files are retained, and the
more messages your organization processes, then the greater the amount
of space that will be required.
We have seen cases where a monitoring
solution has been deployed that increased the duration for which
message tracking logs were kept. The customer had not changed the
location for the tracking logs, and they were still on the system drive
when, a few weeks later, the customer's systems began running out of
space. (Luckily, their monitoring system spotted this before it
affected the system.) The bottom line is that even though these files
are not especially large, they are stored within the default
installation path unless moved and thus could potentially cause a
problem down the line. Trending the storage space required over time is
useful, although not typically vital.
NETWORK UTILIZATION TRENDING
Network utilization trending data has
always been a critical resource for Exchange. It is becoming more and
more important, however, as organizations look to consolidate
datacenter locations and synchronize data between them to improve
resilience to failure scenarios. The most important thing about network
usage trending is to be aware of the data direction. Most network links
are full duplex; this means that they can transfer data in both
directions at the same time, although not necessarily at the same speed.
Network links may be synchronous (same
speed, both ways) or asynchronous (faster one way than the other). This
is an important differentiation since when we are planning and trending
network usage, we need to specify in which direction the data is
moving, for example, from Server1 to Server2 or from load balancer to
client. By far the two most important areas of Exchange network
utilization are from Exchange to the end user and replication traffic
between DAG nodes.
End-user network traffic is typically
asynchronous, with much more data passing from the Exchange service to
the client than vice versa. If there is insufficient network capacity
to meet end-user requirements, then network latency will increase. Latency
is a value that expresses how long network data packets take to pass
between hosts. As network latency increases, the end-user experience
will begin to slow down due to data and operations taking longer to
perform.
DAG replication traffic is generated to
keep database copies up to date and their associated CI. Database
replication traffic is very asynchronous, and it occurs almost entirely
between the active database copy and the replica copies. If the network
link used for this replication traffic is insufficient, latency will
rise, and this may lead to a delay in transaction logs being copied to
replicas. This could be important since the delay in copying
transaction log files between database copies increases the recovery point objective (RPO).
RPO is a value stating how much data you are prepared to lose in the
event of a failure within your service. Obviously, if a failure occurs
and the replica copy is 100 log files behind the active copy, then you
have lost at least 100 MB of data on that database. Monitoring network
links used for replication and attempting to trend capacity usage
changes during the day can help prevent unexpected data loss during a
failure.
Many organizations already have some form
of enterprise network link-monitoring software. Not all of these
programs, however, will perform trending of the usage patterns. The Multi Router Traffic Grapher (MRTG)
provides the most common data by far. This is partly because it is free
and partly because it uses Simple Network Management Protocol (SNMP) to
query routers, switches, and load balancers, so it's a relatively
straightforward process to get the data you need. MRTG displays this
data in real time and historically in chart format. However, it will
not show predicted future trends, and thus this will have to be
performed manually.
Figure 1
shows sample output from MRTG taken from my home broadband router.
(None of my customers wanted to share their link data!) You can see
from the chart that there are periods of 100 percent link utilization.
In my case, this is usually for synchronizing data to SkyDrive or
downloading ISO files from MSDN. In an enterprise environment, this
could easily be a scheduled backup occurring or perhaps someone
reseeding an Exchange database across the network. Short periods of 100
percent utilization on a network link are relatively normal. However,
those periods should be relatively short and ideally infrequent during
the work day.
FIGURE 1. Sample network utilization graph from MRTG
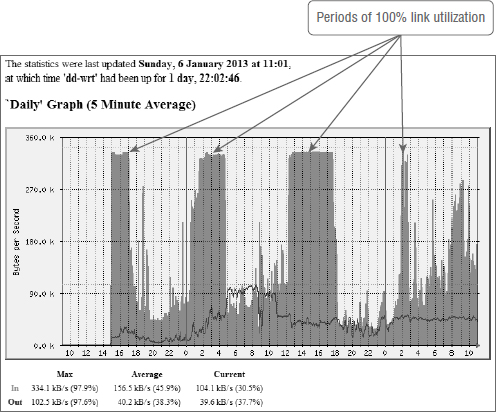
Monitoring and
trending network usage are relatively easy, but they're only half the
story. As mentioned earlier, network latency tends to have the most
dramatic effect on data throughput and client experience.
Network latency is usually expressed as round-trip time (RTT)
in milliseconds. It is common for network teams to monitor link latency
within their datacenters between switches and routers. Nonetheless, it
is not always common for this data to be used for future trend
prediction.
System resource trending is the process of
recording how servers within the Exchange service are using their
critical system resources such as the processor, memory, and disk.
Additionally, it is often useful to trend some key Exchange performance
counters such as RPC Averaged Latency. RPC Averaged Latency is a very
special counter for Exchange, since it essentially shows the average
time taken for Exchange to satisfy the previous 1024 RPC packets. We
highly recommend trending the MSExchange RpcClientAccess\RPC Averaged Latency value for all servers within your Exchange 2013 service.
Many teams perform this type of trending
simply by recording performance monitor counters via the standard
Performance Monitor tool included with Windows. Other customers prefer
to use a third-party tool to do this. The most important thing about
resource trending as opposed to alerting is that you are trying to
predict when the system will begin to trigger alert thresholds.
Service usage trending is performed by recording historical information about how
the service was used and then attempting to predict future growth
patterns. This may include the number of active users on the system,
the number of messages processed, the number of TCP connections, or
Exchange performance counters such as RPC Operations/sec. Service usage
trending is primarily used to justify changes in system performance
behavior.
Imagine a scenario where the RPC Averaged
Latency during the workday has gradually increased from 5 ms to 10 ms
over a three-month period. Although this is useful information, you
need to determine what is causing this change. Do you have more users
on the system? Are the users working harder (increase in RPC
Operations/sec)? Have you reached a system bottleneck (system resource
exhaustion, processor, disk, memory, and so on)?
The job of service usage data is to help
you understand what the customers of the service are doing, when they
do it, and how their behavior impacts the performance of your Exchange
service.
Recording failure occurrence is something
that most organizations do as a matter of course, largely due to the
mass introduction of the Information Technology Infrastructure Library (ITIL),
which also recommends trending of problems. From a trending
perspective, however, you are interested in when the problem occurred,
how significant it was, whether it is happening regularly, and whether
we can do anything to stop it from happening again.
Matt also provided one additional piece of
advice, and that was to evaluate data corruption events seriously and
quickly. Exchange 2010 introduced ESE lost flush detection.
This is a form of logical data corruption that could impact all
database copies, and these events should trigger the highest possible
level of alerting and receive immediate attention. Any event that
results in database corruption should be considered an extreme high
priority. You must work to understand, resolve, and take action on such events immediately and to prevent them from occurring in the future.
USING EXCEL TO PREDICT TRENDS
We have talked about some interesting things to
record and trend so far, but we have not discussed how to perform
trending. Our favorite way to deal with trending is by using Excel.
Ideally, this process should be completed roughly every three months,
although some organizations do this on an annual basis only. The
process begins with collecting the data and then converting it into a
usable format. The potential sources of data are too varied to discuss
here. Nevertheless, you'll eventually want something that you can
import into Excel, ideally in a comma-separated value (CSV) format.
Once the data is in Excel, you can plot it
against time and then use one of the Excel trend-line functions. Excel
provides six options: Exponential, Linear, Logarithmic, Polynomial,
Power, and Moving Average. Our advice is to begin by adding Linear
trending to your chart and then experiment with the other options to
find the best fit.
Figure 2
illustrates our recommended approach to trending. This example shows
the disk LUN capacity data for a mailbox database. In this example, the
customer wanted to know when their database LUNs would reach 65 percent
capacity in order to allow them sufficient time to commission more
storage. The chart shows two sets of data, an initial prediction based
on 12 months of historical data and another prediction based on 24
months of historical data. A trend was identified and a prediction date
derived for when the LUN would reach 65 percent capacity.
FIGURE 2 Example trend chart in Excel
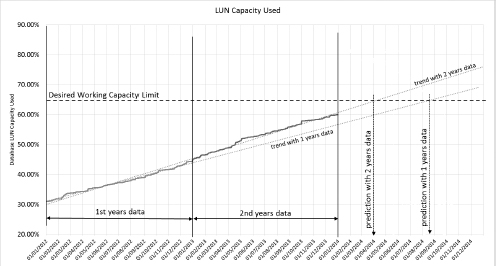
Initially, the historical data was plotted
against the date axis and then a linear trend line was added. In this
case, a linear prediction fits our data very well. We then drew a line
at 65 percent capacity and looked to see where the trend line crossed
the 65 percent capacity line. If we draw a line directly down to the
date axis, this will give us a predicted date when the LUN will reach
65 percent capacity.
Figure 2
shows clearly that our prediction may change as more data is analyzed.
This is why it is important to reevaluate your trending predictions
regularly. We recommend that you update trending predictions quarterly.
As stated previously, though, the farther
into the future the prediction looks, the less accurate it is likely to
be. Likewise, the more historical data you have, the more likely the
prediction is going to be accurate.
As a general
rule, do not attempt to predict any farther into the future than the
amount of historical data you have. That is, if you have 12 months'
worth of data, only predict 12 months into the future. Attempting to
apply a relatively short historical sample to predict well into the
future is little more than guesswork and is unlikely to be accurate.