Predicting the future is a risky business,
but if there's one thing that's guaranteed in future databases, it's an
ever-growing volume of data to store, manage, and back up. Growing
regulatory requirements, the plummeting cost of disk storage, and new
types of information such as digitized video are converging to create
what some call an information storage explosion.
Managing this information while making it readily accessible to a wide
variety of client applications is a challenge for all involved,
particularly the DBA. Fortunately, SQL Server 2008 delivers a number of
new features and enhancements to assist DBAs in this regard.
In
the previous section we looked at the FileStream data type, which
enhances the storage options for BLOB data. One of the great things
about FileStream is the ability to have BLOBs stored outside the database on compressed NTFS volumes. Until SQL Server 2008, compressing data inside
the database was limited to basic options such as variable-length
columns, or complex options such as custom-developed compression
routines.
In this section, we'll focus on a
new feature in SQL Server 2008, data compression, which enables us to
natively compress data inside the database without requiring any
application changes. We'll begin with an overview of data compression
and its advantages before looking at the two main ways in which SQL
Server implements it. We'll finish with a number of important
considerations in designing and implementing a compressed database.
1. Data compression overview
Data
compression, available only in the Enterprise edition of SQL Server
2008, allows you to compress individual tables and indexes using either
page compression or row compression, both of which we'll cover shortly.
Due to its potentially adverse impact on performance, there's no option
to compress the entire database in one action.
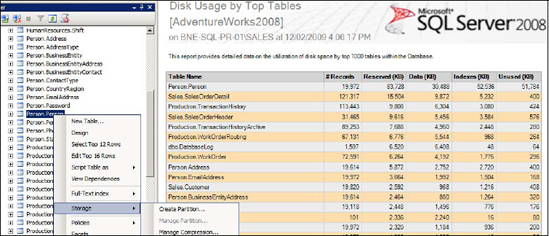
As you can see in figure 1, you can manage a table's compression by right-clicking it and choosing Storage > Manage Compression.
When considering compression in a broad sense, lossy and lossless
are terms used to categorize the compression method used. Lossy
compression techniques are used in situations where a certain level of
data loss between the compressed and uncompressed file is accepted as a
consequence of gaining higher and faster compression rates. JPEG images
are a good example of lossy compression, where a reduction in data
quality between the original image and the compressed JPEG is
acceptable. Video and audio streaming are other common applications for
lossy compression. It goes without saying that lossy compression is
unacceptable in a database environment.
SQL
Server implements its own custom lossless compression algorithm and
attempts to strike a balance between high compression rates and low CPU
overhead. Compression rates and overhead will vary, and are dependent
on a number of factors that we'll discuss, including fragmentation
levels, the compression method chosen, and the nature of the data being
compressed.
Arguably the most powerful
aspect of SQL Server's implementation of data compression is the fact
that the compressed data remains compressed, on disk and
in the buffer cache, until it's actually required, at which point only
the individual columns that are required are uncompressed. Compared to
a file system-based compression solution, this results in the lowest
CPU overhead while maximizing cache efficiency, and is clearly tailored
toward the unique needs of a database management system.
Let's consider some of the benefits of data compression:
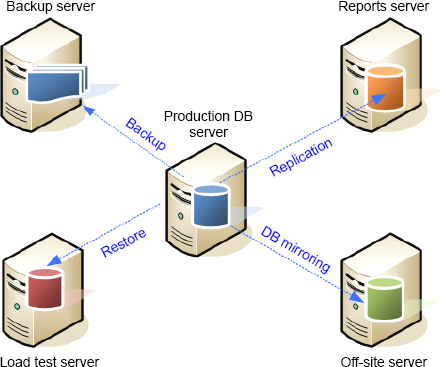
Lower storage costs—Despite
the rapidly decreasing cost of retail storage, storage found in
high-end SANs, typically used by SQL Server implementations, is
certainly not cheap, particularly when considering actual:usable RAID ratios and duplication of data for various purposes, as figure 2 shows.
Lower administration costs—As
databases grow in size, disk I/O-bound administration tasks such as
backups, DBCC checks, and index maintenance take longer and longer. By
compressing certain parts of the database, we're able to reduce the
administration impact. For example, a database that's compressed to
half its size will take roughly half the time to back up.
RAM and disk efficiency—As
mentioned earlier, compressed data read into the buffer cache will
remain compressed until required, effectively boosting the buffer size.
Further, as the data is compressed on disk, the same quantity of disk
time will effectively read more data, thus boosting disk performance as
well.
SQL
Server 2008 implements two different methods of data compression: page
compression and row compression. The makeup of the data in the table or
index determines which of these two will yield the best outcome. As
we'll see shortly, we can use supplied tools to estimate the
effectiveness of each method before proceeding.
2. Row compression
Row
compression extends the variable-length storage format found in
previous versions of SQL Server to all fixed-length data types. For
example, in the same manner that the varchar data type is used to
reduce the storage footprint of variable length strings, SQL Server
2008 can compress integer, char, and float data in the same manner.
Crucially, the compression of fixed-length data doesn't expose the data
type any differently to applications, so the benefits of compression
are gained without requiring any application changes.
As
an example, consider a table with millions of rows containing an
integer column with a maximum value of 19. We could convert the column
to tinyint, but not if we need to support the possibility of much
larger values. In this example, significant disk savings could be
derived through row compression, without requiring any application
changes.
An alternative to row compression is page compression, our next topic.
3. Page compression
In contrast to row compression, page compression, as the name suggests, operates at the page level and uses techniques known as page-dictionary and column-prefix
to identify common data patterns in rows on each page of the compressed
object. When common patterns are found, they're stored once on the
page, with references made to the common storage in place of the
original data pattern. In addition to these methods, page compression
includes row compression, therefore delivering the highest compression
rate of the two options.
Page
compression removes redundant storage of data. Consider an example of a
large table containing columns with a default value specification. If a
large percentage of the table's rows have the default value, there's
obviously a good opportunity to store this value once on each page and
refer all instances of that value to the common store.
Compressing
a table, using either the page or row technique, involves a
considerable amount of work by the SQL Server engine. To ensure the
benefits outweigh the costs, you must take a number of factors into
account.