2. Page-Level Compression
Page-level compression is an implementation of true
data compression, using both column prefix and dictionary-based
compression. Data is compressed be storing repeating values or common
prefixes only once and then referencing those values from other columns
and rows. When you implement page compression for a table, row
compression is applied as well. Page-level compression offers increased
data compression over row-level compression alone but at the expense of
greater CPU utilization. It works using these techniques:
First, row-level data compression is applied to fit as many rows as it can on a single page.
Next,
column prefix compression is run. Essentially, repeating patterns of
data at the beginning of the values of a given column are removed and
substituted with an abbreviated reference, which is stored in the
compression information (CI) structure stored after the page header.
Finally,
dictionary compression is applied on the page. Dictionary compression
searches for repeated values anywhere on a page and stores them in the
CI.
Page compression is applied only after a page is full
and if SQL Server determines that compressing a page will save a
meaningful amount of space.
The amount of compression provided by page-level data
compression is highly dependent on the data stored in a table or index.
If a lot of the data repeats itself, compression is more efficient. If
the data is more randomly discrete values, fewer benefits are gained
from using page-level compression.
Column prefix compression looks at the column values
on a single page and chooses a common prefix that can be used to reduce
the storage space required for values in that column. The longest value
in the column that contains the prefix is chosen as the anchor value. A
row that represents the prefix values for each column is created and
stored in the CI structure that immediately follows the page header.
Each column is then stored as a delta from the anchor value, where
repeated prefix values in the column are replaced by a reference to the
corresponding prefix. If the value in a row does not exactly match the
selected prefix value, a partial match can still be indicated.
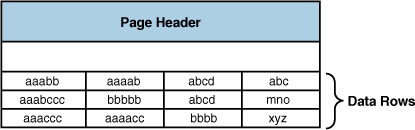
For example, consider a page that contains the following data rows before prefix compression as shown in Figure 2.
After you apply column prefix compression on the
page, the CI structure is stored after the page header holding the
prefix values for each column. The columns then are stored as the
difference between the prefix and column value, as shown in Figure 3.
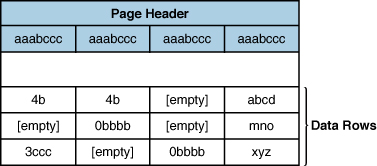
In the first column in the first data row, the value 4b represents that the first four characters of the prefix (aaab) are present at the beginning of the column for that row and also the character b. If you append the character b to the first four values of the prefix, it rebuilds the original value of aaabb. For any columns values that are [empty], the column matches the prefix value exactly. Any column value that starts with 0
means that none of the first characters of the column match the prefix.
For the fourth column, there is no common prefix value in the columns,
so no prefix value is stored in the CI structure.
After column prefix compression is applied to every
column individually on the page, SQL Server then looks to apply
dictionary compression. Dictionary compression looks for repeated values
anywhere on the page and also stores them in the CI structure after the
column prefix values. Dictionary compression values replace repeated
values anywhere on a page. The following illustrates the same page shown
previously after dictionary compression has been applied:
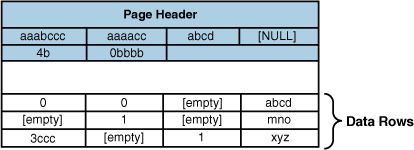
The dictionary is stored as a set of these duplicate
values and a symbol to represent these values in the columns on the
page. As you can see in this example, 4b is repeated in multiple columns in multiple rows, and the value is replaced by the symbol 0 throughout the page. The value 0bbbb is replaced by the symbol 1.
SQL Server recognizes that the value stored in the column is a symbol
and not a data value by examining the coding in the CD array, as
discussed earlier.
Not all pages contain both the prefix record and a
dictionary. Having them both depends on whether the data has enough
repeating values or patterns to warrant either a prefix record or a
dictionary.
3. The CI Record
The
CI record is the only main structural change to a page when it is page
compressed versus a page that uses row compression only. As shown in the
previous examples, the CI record is located immediately after the page
header. There is no entry for the CI record in the row offset table
because its location is always the same. A bit is set in the page header
to indicate whether the page is page compressed. When this bit is
present, SQL Server knows to look for the CI record. The CI record
contains the data elements shown in Table 1.
Table 1. Data Elements Within the CI Record
| Name | Description |
|---|
| Header | This structure contains 1 byte to keep track of information about the CI. Bit 0 is the version (currently always 0), Bit 1 indicates the presence of a column prefix anchor record, and Bit 2 indicates the presence of a compression dictionary. |
| PageModCount | This
value keeps track of the number of changes to the page to determine
whether the compression on the page should be reevaluated and the CI
record rebuilt. |
| Offsets | This
element contains values to help SQL Server find the dictionary. It
contains the offset of the end of the Column prefix anchor record and
offset of the end of the CI record itself. |
| Anchor Record | This record looks exactly like a regular CD record (see Figure 1). Values stored are the common prefix values for each column, some of which might be NULL. |
| Dictionary | The
first 2 bytes represent the number of entries in the dictionary,
followed by an offset array of 2-byte entries, which indicate the end
offset of each dictionary entry, and then the actual dictionary values. |