A table is logically defined as a set of columns with
certain properties, such as the data type, nullability, constraints,
and so on.
Internally, a table is contained in one or more partitions. A partition
is a user-defined unit of data organization. By default, a table has at
least one partition that contains all the table pages. This partition
resides in a single filegroup, as described earlier. When a table has
multiple partitions, the data is partitioned horizontally so that groups
of rows are mapped into individual partitions, based on a specified
column. The partitions can be placed in one or more filegroups in the
database. The table is treated as a single logical entity when queries
or updates are performed on the data. Figure 1 shows the organization of a table in SQL Server 2008.
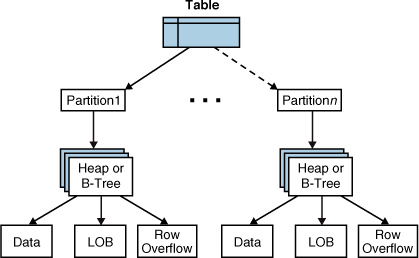
Each table has one row in the sys.objects catalog view, and each table and index in a database is represented by a single row in the sys.indexes catalog view. Each partition of a table or index is represented by one or more rows in the sys.partitions
catalog view. Each partition can have three types of data, each stored
on its own set of pages: in-row data pages, row-overflow pages, and LOB
data pages. Each of these types of pages has an allocation unit, which
is contained in the sys.allocation_units view. There is always
at least one allocation unit for the in-row data. The following sample
query shows how to view the partition and allocation information for the
databaselog and currency tables in the AdventureWorks2008R2 database:
use AdventureWorks2008R2
go
SELECT convert(varchar(15), o.name) AS table_name,
p.index_id as indid,
convert(varchar(30), i.name) AS index_name ,
convert(varchar(18), au.type_desc) AS allocation_type,
au.data_pages as d_pgs,
partition_number as ptn
FROM sys.allocation_units AS au
JOIN sys.partitions AS p ON au.container_id = p.partition_id
JOIN sys.objects AS o ON p.object_id = o.object_id
JOIN sys.indexes AS i ON p.index_id = i.index_id AND i.object_id = p.object_id
WHERE o.name = N'databaselog' OR o.name = N'currency'
ORDER BY o.name, p.index_id;
table_name indid index_name allocation_type d_pgs ptn
----------- ----- ---------------------------- ----------------- ----- ---
Currency 1 PK_Currency_CurrencyCode IN_ROW_DATA 1 1
Currency 2 AK_Currency_Name IN_ROW_DATA 1 1
DatabaseLog 0 NULL IN_ROW_DATA 753 1
DatabaseLog 0 NULL LOB_DATA 0 1
DatabaseLog 0 NULL ROW_OVERFLOW_DATA 0 1
DatabaseLog 2 PK_DatabaseLog_DatabaseLogID IN_ROW_DATA 3 1
In this example, you can see that the DatabaseLog
table (which is a heap table) has three allocation units associated
with the table—LOB, row-overflow, and in-row data—and one allocation
unit for the nonclustered index PK_DatabaseLog_DatabaseLogID. The currency table (which is a clustered table) has a single in-row allocation unit for both the table (index_id = 1) and the nonclustered index (AK_Currency_Name).
In SQL Server 2008, there are two types of tables: heap tables and clustered tables. Let’s look at how they are stored.
Heap Tables
A table without a clustered index is a heap table.
There is no imposed ordering of the data rows for a heap table.
Additionally, there is no direct linkage between the pages in a heap
table.
By default, a heap has a single partition. Heaps have one row in sys.partitions, with an index ID of 0
for each partition used by the heap. When a heap has multiple
partitions, each partition has a heap structure that contains the data
for that specific partition. For example, if a heap has four partitions,
there are four heap structures (one in each partition) and four rows in
sys.partitions.
Depending on the data types in the heap, each heap
structure has one or more allocation units to store and manage the data
for each partition. At a minimum, each heap has one IN_ROW_DATA allocation unit per partition. The heap also has one LOB_DATA allocation unit per partition, if it contains large object columns. It also has one ROW_OVERFLOW_DATA allocation unit per partition if it contains variable-length columns that exceed the 8,060-byte row size limit.
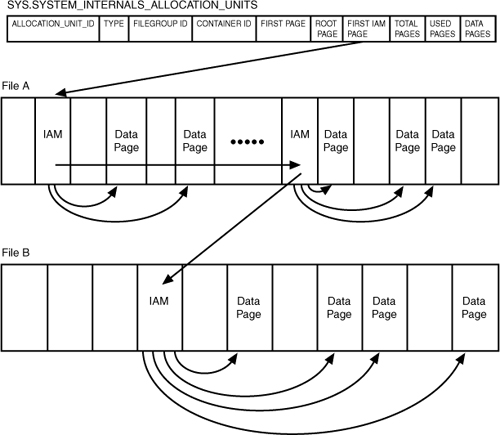
To access the contents of a heap, SQL Server uses the
IAM pages. In SQL Server 2008, each heap table has at least one IAM
page. The address of the first IAM page is available in the undocumented
sys.sytem_internals_allocation_units system view. The column first_iam_page
points to the first IAM page in the chain of IAM pages that manage the
space allocated to the heap in a specific partition. The following query
returns the first IAM pages for each of the allocation units for the
heap table DatabaseLog in AdventureWorks2008R2:
use AdventureWorks2008R2
go
select p.partition_number as ptn,
type_desc,
filegroup_id,
first_iam_page
from sys.system_internals_allocation_units i
inner join
sys.partitions p
on p.hobt_id = i.container_id
where p.object_id = OBJECT_ID('DatabaseLog')
and index_id = 0
go
ptn type_desc filegroup_id first_iam_page
----------- -------------------- ------------ --------------
1 IN_ROW_DATA 1 0xAA0000000100
1 LOB_DATA 1 0xB90000000100
1 ROW_OVERFLOW_DATA 1 0x000000000000
Note that the value 0x000000000000 for the first_iam_page for ROW_OVERFLOW_DATA indicates that no extents have yet been allocated for storing row-overflow data.
Note
The sys.system_internals_allocation_units
system view is reserved for Microsoft SQL Server internal use only.
Future compatibility and availability of this view is not guaranteed.
The data pages and rows in the heap are not sorted in
any specific order and are not linked. The IAM page registers which
extents are used by the table. SQL Server can then simply scan the
allocated extents referenced by the IAM page, in physical order. This
essentially avoids the problem of page chain fragmentation during reads
because SQL Server always reads full extents in sequential order. Using
the IAM pages to set the scan sequence also means that rows from the
heap often are not returned in the order in which they were inserted.
As discussed earlier, each IAM can map a maximum of
63,903 extents for a table. As a table uses extents beyond the range of
those 63,903 extents, more IAM pages are created for the heap table as
needed. A heap table also has at least one IAM page for each file on
which the heap table has extents allocated. Figure 2 illustrates the structure of a heap and how its contents are traversed using the IAM pages.
Clustered Tables
A clustered table is
a table that has a clustered index defined on it. When you create a
clustered index, the data rows in the table are physically sorted in the
order of the columns in the index key. The data pages are chained
together in a doubly linked list (each page points to the next page and
to the previous page). Normally, data pages are not linked. Only index
pages within a level are linked in this manner to allow for ordered
scans of the data in an index level. Because the data pages of a
clustered table constitute the leaf level of the clustered index, they
are chained as well. This allows for an ordered table scan. The page
pointers are stored in the page header. Figure 3 shows a simplified example of the data pages of a clustered table. (Note that the figure shows only the data pages.)
