When you run a query against a table that has no
indexes, SQL Server has to read every page of the table, looking at
every row on each page to find out whether each row satisfies the search
arguments. SQL Server has to scan all the pages because there’s no way
of knowing whether any rows found are the only rows that satisfy the
search arguments. This search method is referred to as a table scan.
A table scan is not
an efficient way to retrieve data unless you really need to retrieve all
rows. The Query Optimizer in SQL Server always calculates the cost of
performing a table scan and uses that as a baseline when evaluating
other access methods.
Suppose that a table is stored on 10,000 pages; even
if only one row is to be returned or modified, all the pages must be
searched, resulting in a scan of approximately 80MB of data (that is,
10,000 pages × 8KB per page = 80,000KB).
Indexes are structures stored separately from the
actual data pages; they contain pointers to data pages or data rows.
Indexes are used to speed up access to the data; they are also the
mechanism used to enforce the uniqueness of key values.
Indexes in SQL Server are balanced trees. There is a single root page at the top of the tree, which branches out into N
pages at each intermediate level until it reaches the bottom (leaf
level) of the index. The leaf level has one row stored for each row in
the table. The index tree is traversed by following pointers from the
upper-level pages down through the lower-level pages. Each level of the index is linked as a doubly linked list.
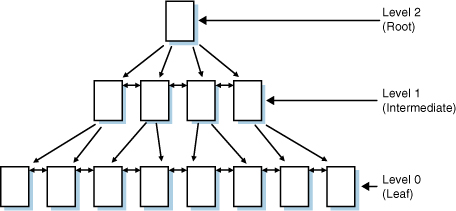
An index can have many intermediate levels, depending
on the number of rows in the table, index type, and index key width.
The maximum number of columns in an index is 16; the maximum width of an
index row is 900 bytes.
To provide a more efficient mechanism to identify and
locate specific rows within a table quickly and easily, SQL Server
supports two types of indexes: clustered and nonclustered.
1. Clustered Indexes
When you create a clustered index, all rows in the
table are sorted and stored in the clustered index key order. Because
the rows are physically sorted by the index key, you can have only one
clustered index per table. You can think of the structure of a clustered
index as being similar to a filing cabinet: the data pages are like
folders in a file drawer in alphabetical order, and the data rows are
like the records in the file folder, also in sorted order.
You can think of the intermediate levels of the index
tree as the file drawers, also in alphabetical order, that assist you
in finding the appropriate file folder. Figure 2 shows an example of a clustered index tree structure.
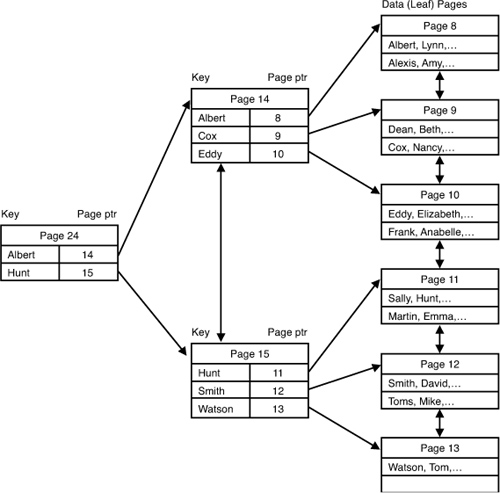
In Figure 2,
note that the data page chain is in clustered index order. However, the
rows on each page might not be physically sorted in clustered index
order, depending on when rows were inserted or deleted in the page. SQL
Server still keeps the proper sort order of the rows via the row IDs and
the row offset table. A clustered index is useful for range-retrieval
queries or searches against columns with duplicate values because the
rows within the range are physically located in the same page or on
adjacent pages.
The data pages of the table are also the leaf level
of a clustered index. To find all clustered index key values, SQL Server
must eventually scan all the data pages.
SQL Server performs the following steps when searching for a value using a clustered index:
1. | Queries the system catalogs for the page address for the root page of the index. (For a clustered index, the root_page column in sys.system_internals_allocation_units points to the top of the clustered index for a specific partition.)
|
2. | Compares the search value against the key values stored on the root page.
|
3. | Finds the highest key value on the page where the key value is less than or equal to the search value.
|
4. | Follows the page pointer stored with the key to the appropriate page at the next level down in the index.
|
5. | Continues following page pointers (that is, repeats steps 3 and 4) until the data page is reached.
|
6. | Searches
the rows on the data page to locate any matches for the search value.
If no matching row is found on that data page, the table contains no
matching values.
|
By default, a clustered index has a single partition and thus has at least one row in sys.partitions with index_id = 1. When a clustered index has multiple partitions, a separate B-tree structure contains the data for that specific partition.
Depending on the data types in the clustered index,
each clustered index structure has one or more allocation units in which
to store and manage the data for a specific partition. At a minimum,
each clustered index has one IN_ROW_DATA allocation unit per partition. If the table contains any LOB data, the clustered index also has one LOB_DATA allocation unit per partition and one ROW_OVERFLOW_DATA allocation unit per partition if the table contains any variable-length columns that exceed the 8,060-byte row size limit.
Clustered Index Row Structure
The structure of a clustered index row is similar to
the structure of a data row except that it contains only key columns;
this structure is detailed in Figure 3.
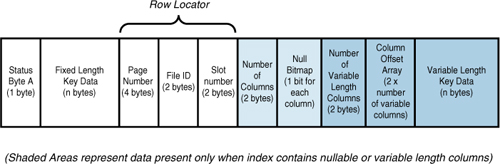
Notice
that unlike a data row, index rows do not contain the status byte B or
the 2 bytes to hold the length of fixed-length data fields. Instead of
storing the length of the fixed-length data, which also indicates where
the fixed-length portion of a row ends and the variable-length portion
begins, the page header pminlen value is used to help describe an index row. The pminlen
value is the minimum length of the index row, which is essentially the
sum of the size of all fixed-width fields and overhead. Therefore, if no
variable-length or nullable fields are in the index key, pminlen also indicates the width of each index row.
The null bitmap field and field for the number of
columns in the index row are present only when an index key contains
nullable columns. The number of columns value is only needed to
determine how many bits are needed in the null bitmap and therefore how
many bytes are required to store the null bitmap (1 byte per eight
columns). The data contents of a clustered index row include the key
values along with a 6-byte down-page pointer (the first 2 bytes are the
file ID, and the last 4 bytes are the page number). The down-page
pointer is the last value in the fixed-data portion of the row.
Nonunique Clustered Indexes
When a clustered index is defined on a table, the
clustered index keys are used as row locators to identify the data rows
being referenced by nonclustered indexes (more on this topic in the
following section on nonclustered indexes). Because the clustered keys
are used as unique row pointers, there needs to be a way to uniquely
refer to each row in the table. If the clustered index is defined as a
unique index, the key itself uniquely identifies every row. If the
clustered index was not created as a unique index, SQL Server adds a
4-byte integer field, called a uniqueifier,
to the data row to make each key unique when necessary. When is the
uniqueifier necessary? SQL Server adds the uniqueifier to a row when the
row is added to a table and that new row contains a key that is a
duplicate of the key for an already-existing row.
The uniqueifier is added to the variable-length data
area of the data row, which also results in the addition of the
variable-length overhead bytes. Therefore, each duplicate row in a
clustered index has a minimum of 4 bytes of overhead added for the
additional uniqueifier.
If the row had no variable-length keys previously, an additional 8 bytes
of overhead are added to the row to store the uniqueifier (4 bytes)
plus the overhead bytes required for the variable data (storing the
number of variable columns requires 2 bytes, and the column offset array
requires 2 bytes).