2. Nonclustered Indexes
A nonclustered index is a separate index structure,
independent of the physical sort order of the data rows in the table.
You can have up to 999 nonclustered indexes per table.
A nonclustered index is similar to the index in the
back of a book. To find the pages on which a specific subject is
discussed, you look up the subject in the index and then go to the pages
referenced in the index. This method is efficient as long as the
subject is discussed on only a few pages. If the subject is discussed on
many pages, or if you want to read about many subjects, it can be more
efficient to read the entire book.
A nonclustered index works similarly to the book
index. From the index’s perspective, the data rows are randomly spread
throughout the table. The nonclustered index tree contains the index key
values, in sorted order. There is a row at the leaf level of the index
for each data row in the table. Each leaf-level row contains a data row
locator to locate the actual data row in the table.
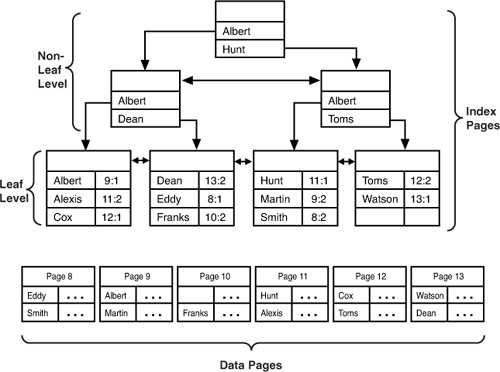
If no clustered index is created for the table, the
data row locator for the leaf level of the index is an actual pointer to
the data page and the row number within the page where the row is
located (see Figure 4).
Nonclustered indexes on clustered tables use the
associated clustered index key value for the record as the data row
locator. When SQL Server reaches the leaf level of a nonclustered index,
it uses the clustered index key to start searching through the
clustered index to find the actual data row (see Figure 5).
This adds some I/O to the search itself, but the benefit is that if a
page split occurs in a clustered table, or if a data row is moved (for
example, as a result of an update), the nonclustered index row locator
stays the same. As long as the clustered index key value itself is not modified, no data row locators in the nonclustered index have to be updated.
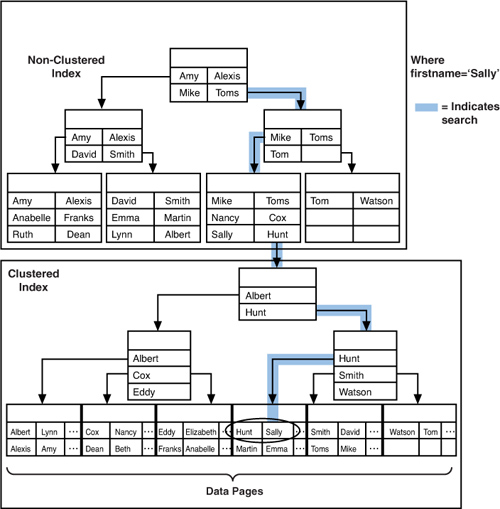
SQL Server performs the following steps when searching for a value by using a nonclustered index:
1. | Queries the system catalog to determine the page address for the root page of the index.
|
2. | Compares the search value against the index key values on the root page.
|
3. | Finds the highest key value on the page where the key value is less than or equal to the search value.
|
4. | Follows the down-page pointer to the next level down in the nonclustered index tree.
|
5. | Continues following page pointers (that is, repeats steps 3 and 4) until the nonclustered index leaf page is reached.
|
6. | Searches
the index key rows on the leaf page to locate any matches for the
search value. If no matching row is found on the leaf page, the table
contains no matching values.
|
7. | If a match is found on the leaf page, SQL Server follows the data row locator to the data row on the data page.
|
Nonclustered Index Leaf Row Structures
In nonclustered indexes, if the row locator is a row
ID, it is stored at the end of the fixed-length data portion of the row.
The rest of the structure of a nonclustered index leaf row is similar
to a clustered index row. Figure 6 shows the structure of a nonclustered leaf row for a heap table.

If the row locator is a clustered index key value,
the row locator resides in either the fixed or variable portion of the
row, depending on whether the clustered key columns were defined as
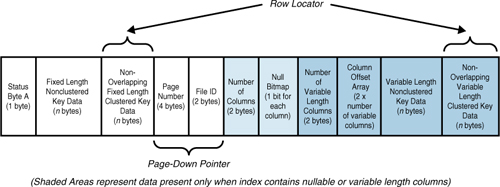
fixed or variable length. Figure 7 shows the structure of a nonclustered leaf row for a clustered table.
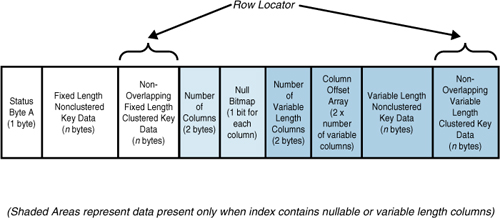
When the row locator is a clustered key value and the
clustered and nonclustered indexes share columns, the data value for
the key is stored only once in the nonclustered index row. For example,
if your clustered index key is on lastname and you have a nonclustered index defined on both firstname and lastname, the index rows do not store the value of lastname twice, but only once for both keys.
Nonclustered Index Nonleaf Row Structures
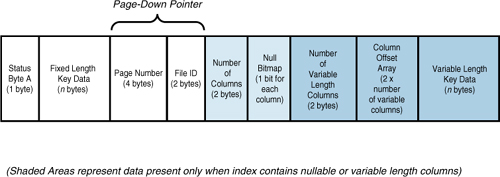
The nonclustered index nonleaf rows are similar in
structure to clustered index nonleaf rows in that they contain a
page-down pointer to a page at the next level down in the index tree.
The nonleaf rows don’t need to point to data rows; they only need to
provide the path to traverse the index tree to a leaf row. If the
nonclustered index is defined as unique, the nonleaf index key row
contains only the index key value and page-down pointer. Figure 8 shows the structure of a nonleaf index row for a unique nonclustered index.
If the nonclustered index is not defined as a unique
index, the nonleaf rows also contain the row locator information for the
corresponding data row. Storing the row locator in the nonleaf index
row ensures each index key row is unique (because the row locator, by
its nature, must be unique). Ensuring each index key row is unique
allows any corresponding nonleaf index rows to be located and deleted
more easily when the data row is deleted. For a heap table, the row
locator is the corresponding data row’s page and row pointer, as shown
in Figure 9.
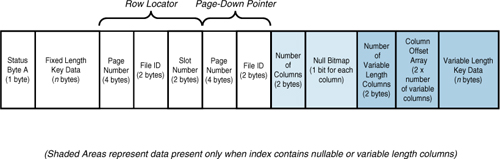
If the table is clustered, the clustered key values
are stored in the nonleaf index rows of the nonunique nonclustered index
just as they are in the leaf rows, as shown in Figure 10.
As you can see, it’s possible for the index pointers
and row overhead to exceed the size of the index key itself. This is
why, for I/O and storage reasons, it is always recommended that you keep
your index keys as small as possible.